- Published on
LLM - Building Applications with APIs
- Authors

- Name
- Ryan Chung
目錄
本篇是 LLM 系列文的第一章,著重在語言模型的基本介紹、多模態分析以及 API 應用。
其他內容請參考以下連結:
- LLM 首部曲: Building Applications with APIs
- LLM 二部曲: Prompting and Alignment (SFT+RL)
- LLM 三部曲: Retrieval Augmented Generation (RAG)
淺談大型語言模型
2022 年 12 月,ChatGPT 的問世給整個世界投下震撼彈。 在這之前,基於深度學習 (deep learning) 的應用大多偏向影像辨識, 例如 從醫療影像辨識出疾病特徵 (eg. CNN),或是 自駕車系統對周遭環境進行物件偵測 (eg. YOLO)。 針對自然語言處理 (NLP) 的應用雖說不是沒有,但侷限在文章分類(例如情感、診斷分析)與簡單的日常互動,還沒有真正改變產業的殺手級應用出現。
然而 ChatGPT 的出現改變了這個局面。 ChatGPT 是由 OpenAI 所開發的人工智慧聊天機器人,雖說是聊天機器人,其功能可不只有聊天那麼簡單。 過去的資料表明,光是其模型的前身 (GPT-3 in 2020) 就用了 45TB 的網路資料做訓練,訓練參數達 175B, 即便放在現在也沒幾家公司訓練的起,更別說新一代的模型 GPT-3.5 ~ 4o,完全是資本的世界。
因為有大量的網路資料作為訓練背景,ChatGPT 具備常人難以企及的知識量。 只要不是特定領域的專業問題或是新技術,幾乎都有辦法侃侃而談。 舉凡創意發想、翻譯、文法修正、整理論文摘要、寫詩寫小說,甚至到解數學、寫程式、debug 都有辦法做到。 近期的版本整合了 DALL-E 模型,甚至能生成圖像和影片。 前陣子一份 MIT 發表在 Science 的研究被廣為流傳 1,生成式人工智慧大幅增加基礎工作的生產力 (37%),讓人不禁懷疑下一次工業革命是否已經到來。
然而 ChatGPT 並不是憑空崛起,他是一個已經默默耕耘數年的 NLP 技術。 2017 年 Google 發表 Transformer 模型 2,包含編碼器 (encoder) 與解碼器 (decoder) 架構,輔以注意力機制 (attention),讓序列資料得以被理解與創造。 其代表的應用就是翻譯 (eg. Seq2Seq),我們可以將英文文章透過編碼器壓縮到某個向量空間(即抽象內容的理解),再透過解碼器解壓縮成某個中文輸出,類似人類閱讀與說話的方式。 可想而知,編碼器著重在文章的理解與分類,知名的模型像是 Google Bert (2018) 3;解碼器則著重在文本的生成,例如 OpenAI 的 GPT 模型 (2018) 4。 更多說明可以參考 Hugging Face 的 這篇文章。
過去幾年,GPT 模型的表現並不好,所受到的關注並沒有 Bert 來得多。 就連作為聊天機器人,Bert 能夠透過上下文的推理,強化對原始問題的理解,回答出更有意義的答案。 相較之下作為內容產生器來訓練的 GPT 模型,顯然胡言亂語與答非所問的狀況更明顯。 過去我曾作為核心成員參加 Google 學生開發者社群 進行 NLP 技術的研究, 也是以 Bert 和 Meta 開發的 Bart (2019) 5 模型作為主要研究方向,鮮少關注以解碼器為主體的 GPT。
然而隨著硬體與軟體技術的同步發展,更強大的 GPU 和有效的訓練與微調方式(例如以人類回饋為基礎的 RLHF),不斷刺激並加速語言模型的發展。 時至今日,主流的聊天機器人如 OpenAI ChatGPT、Google Gemini、Anthropic Claude 或是 Perplexity、 背後都是具備數十億到數千億個參數的超大模型,這些模型又被廣泛稱為「大型語言模型」(large language model, LLM)。 透過大量的訓練與微調,大型語言模型能夠以參數的方式咀嚼並理解人類的語言,提供適當的文字回應, 或是作為思考中樞,進一步呼叫其他專業工具完成工作,例如生成 3D 影像、最佳化生產線等。
本次系列文即是以 LLM 的應用為主,精選三個重要主題做練習,讓我們更加了解如何將大型語言模型運用到專案上。 未來如果還有機會,我會再多分享一些深度學習和類神經網路背後的原理,這次就先從實作面來認識這些重要技術。
建立自己的應用程式
儘管各家聊天機器人都有提供簡潔的介面供一般用戶使用,若要讓大型語言模型運作在自己的應用中,勢必得研究如何使用 LLM 的 API。 以 OpenAI 來說,目前最便宜的模型 GPT-4o mini 價格約 $0.15 / 1M (input) 與 $0.6 / 1M (output) tokens, 以 3%-4% 的價格就能獲得接近 GPT-4o 的能力(參考下圖),可說是相當划算。 如果不想花錢,也可以參考這個 Free ChatGPT 專案,但身為第三方服務有諸多限制且不能保證穩定。
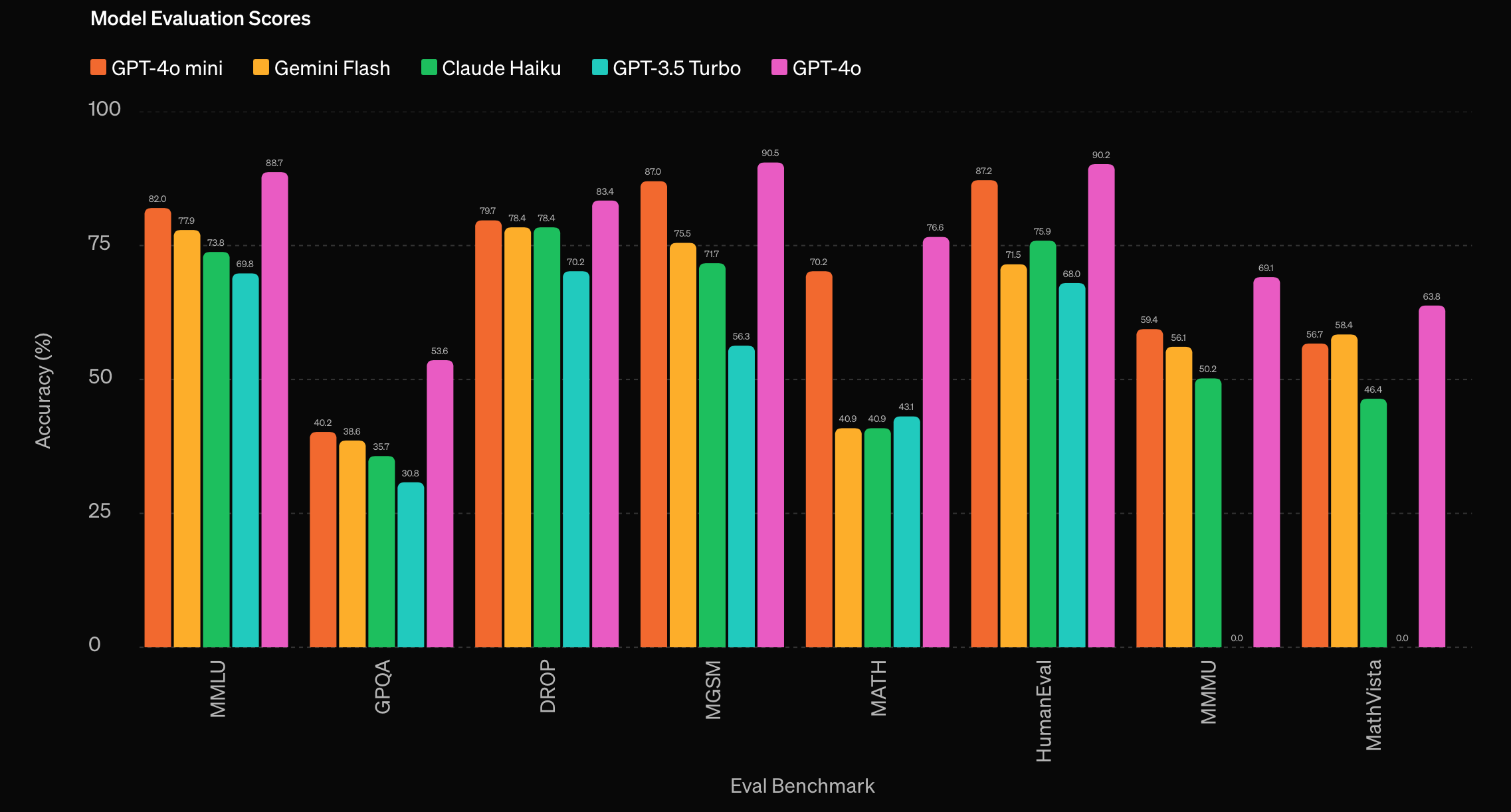
還有一種方式,那就是使用 Google 提供的 Gemini API, 雖然有流量上限,但是對於負載不高的需求來說也是綽綽有餘。 本篇文章即會使用 Gemini API 來開發應用程式。
Gemini API key
首先登入 Google Gemini API 的 首頁,選擇「Get API key in Google AI Studio」進入選單頁面。 同意服務條款後,在左上角 Get API Key 頁籤中選擇 Create API Key in new project,就會自動產生金鑰。 如果無法直接在新專案中產生,也可以點選 Create API Key in existing project,從現有的 Google Cloud 專案中新增金鑰。
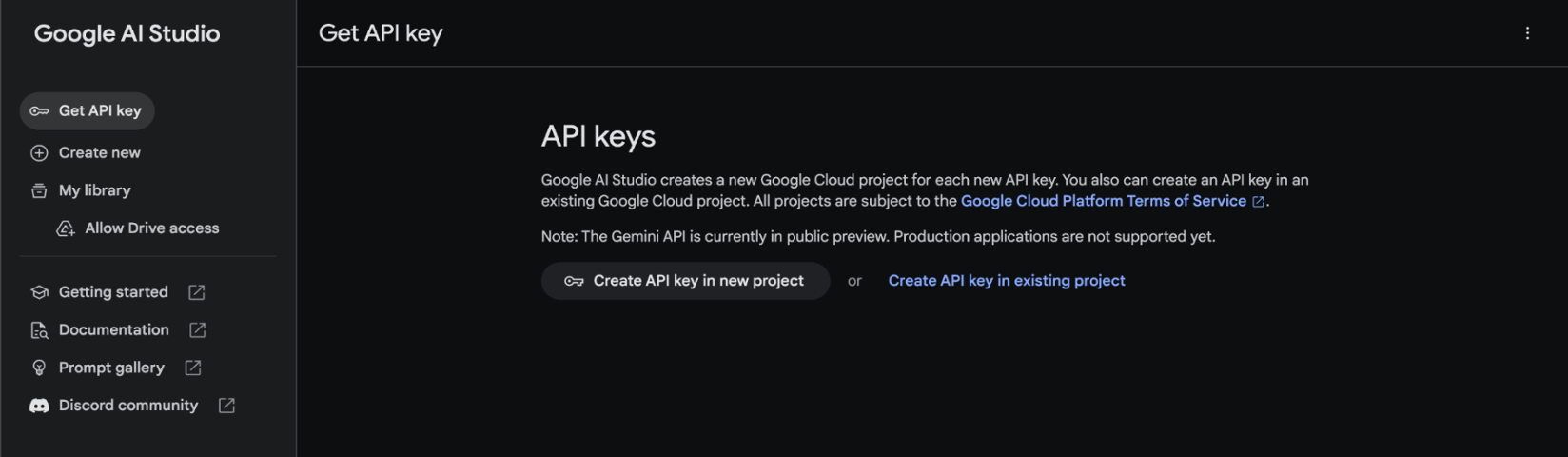
產生完畢後,將 API Key 複製並收好,等下會用到。如果不幸忘記,也可以隨時回到這個頁面重新複製。
接著我們即將開始第一個應用。 首先申明一下,以下的教學內容主要來自 Google Cloud Skills Boost 的 運用 Vertex AI Gemini 1.0 Pro 開發應用程式。 原先是使用雲端環境、Streamlit 與 Vertex AI 的 API 來完成應用程式,我把他簡化並改寫成本地端也能運作的方式。 我們直接使用 Gemini API,就不需要再登入 Google Cloud 存取 Vertex AI。 如果對如何在本地端跑 Vertex AI 有興趣,也可以自行參考 這篇文章。
文字生成
所謂生成式人工智慧,顧名思義就是要來生成內容的。 試想如果我們要生成一篇 100 字的文章,假設每個字元只有 ASCII 中的 128 種組合,那就有 128100 種可能性,約 5.26e+210。 這顯然是個不太可能靠當今的電腦用決策樹算出來的數字,要知道宇宙大概也只有 1082 個原子。
LLM 之所以能做到輕鬆生成超長文章,是因為他把輸出視為一種 「文字接龍」 的遊戲。 也就是說,他用之前輸入與輸出的內容,來預測接下來要輸出什麼字。 例如「我愛人工智慧」的段文字,它在輸出「我愛人...」之後,可能接「人類」、「人妻」等結果,但根據前文認為「人工」的機率最高, 而人工之後要接「智慧」,而不是「呼吸」。 怎麼決定要拿哪個字,取決於背後每個字的機率分佈,以及選字的策略。 這裡就不能不提到三個對生成式人工智慧最重要的輸出參數:Temperature、Top-K、Top-P。
注意這裡我用「字」來簡化理解,實際上不同語言對於「字」定義都不一樣。 例如在英文中,單一字母可能沒什麼意義,組合成單字才有含義。 但是對於中文,單一文字可能就有同等的含義。 實際在運算中,語言模型會把單字分割成無數個 token,再透過預測 token 來組合出文字與文章。 (圖源)

- Temperature (0-1): 決定輸出文字的機率分佈,越高的溫度就會讓機率分佈越平均,增加其他字被選中的機率。換句話說,增加溫度可以增加文章的「創意」程度。
- Top-K (1-N): 從機率前 K 高的文字中做選擇,增加 K 也可以增加其他字被選中的機率。 但我們必須注意離均差的問題,例如有一個字機率是 95% (就是它了!),剩下所有字瓜分那 5%,若 K=2 則無論如何一定要從 5% 的垃圾裡面挑一個字,顯然不一定正確。
- Top-P (0-1): 從前 P 的機率內挑選文字,也就是設定選字的 threshold。個人認為比 Top-K 合理多,但這個就見仁見智。
我們首先進行必要套件的安裝,包含 google-generativeai 套件,以及用來搭建簡易 APP 的套件 Gradio。 可以閱讀 Gemini 文件 與 Gradio 文件 獲得更詳細的說明。
pip install google-generativeai gradio
接著,我們引入套件,並設定好剛才取得的 Gemini API Key。 模型的部分,可以使用 Gemini 1.0、1.5 Pro 和 1.5 Flash,前者較專業但流量限制較多,後者表現稍差但 CP 值較高,可以依照需求自行嘗試。 若一切順利,運行後應該會看到 Set Gemini API sucessfully!! 的輸出。
import google.generativeai as genai
import gradio as gr
# Set up Gemini API key
GOOGLE_API_KEY="<Your-API-Key>"
genai.configure(api_key=GOOGLE_API_KEY)
model = genai.GenerativeModel("gemini-1.5-flash")
# Check if you have set your Gemini API successfully
# You should see "Set Gemini API sucessfully!!" if nothing goes wrong.
try:
model.generate_content("test")
print("Set Gemini API sucessfully!!")
except:
print("There seems to be something wrong with your Gemini API.")
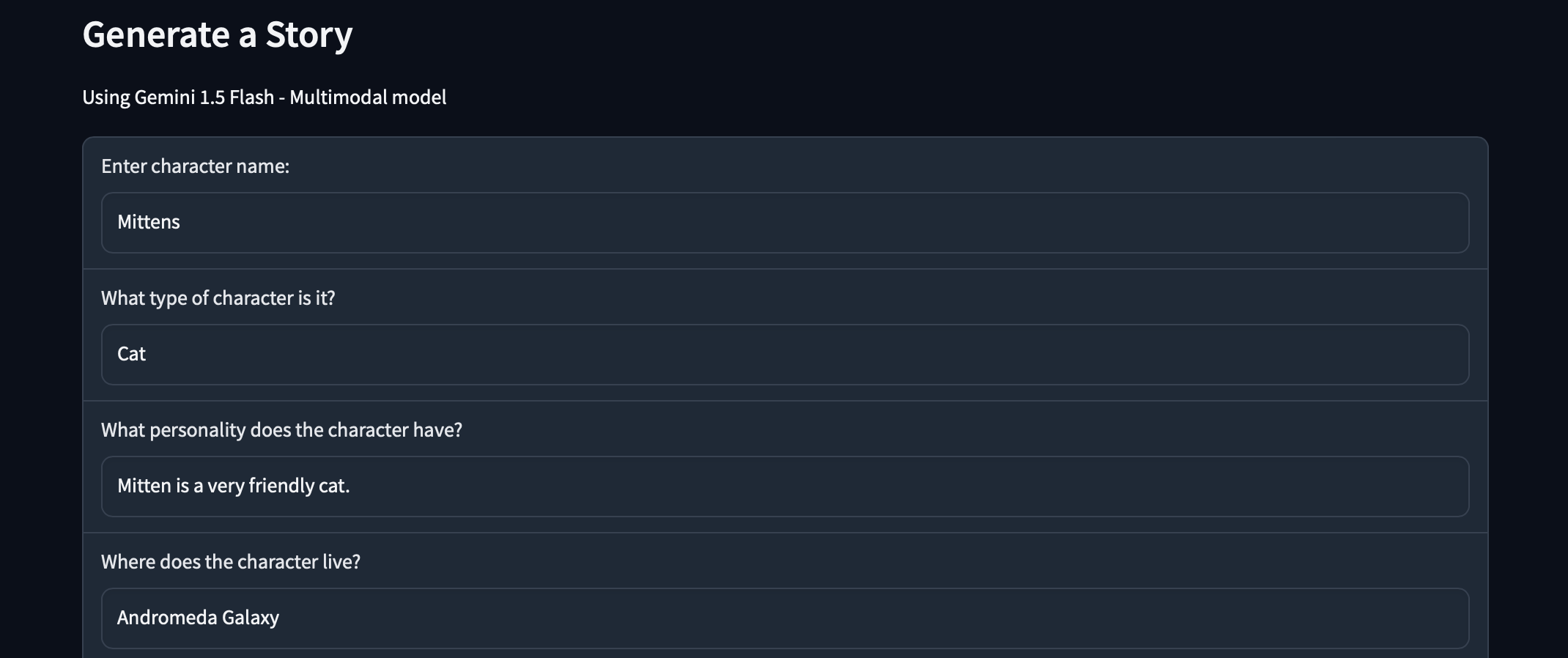
接著我們開始著手透過 Gradio 設計 APP 介面。 我們想要實作一個 故事產生器,包含主要角色的名稱、性格、地點等基本特徵,再加上故事的長度和類型。 可以透過 APP 欄位讓使用者輸入這些項目,再透過 f-string 整合成 LLM 的輸入提示 (prompt)。 只要透過 Gemini API,就可以順利傳送 prompt 並接收其回傳的生成內容,列印在頁面上。 我們可以實際在 localhost 開啟網頁試玩看看。
# construct the Gradio UI interface
with gr.Blocks() as demo:
gr.Markdown("# Generate a Story\nUsing Gemini 1.5 Flash - Multimodal model")
# story character input
character_name = gr.Textbox(label="Enter character name:", value='Mittens')
character_type = gr.Textbox(label="What type of character is it?", value='Cat')
character_persona = gr.Textbox(label="What personality does the character have?", value='Mitten is a very friendly cat.')
character_location = gr.Textbox(label="Where does the character live?", value="Andromeda Galaxy")
# story length and premise
length_of_story = gr.Radio(["Short","Long"], value="Short", label="Select the length of the story:")
story_premise = gr.Dropdown(["Love","Adventure","Mystery","Horror","Comedy","Sci-Fi","Fantasy","Thriller"],
value=["Love","Adventure"], multiselect=True,
label="What is the story premise? (can select multiple)")
temperature = gr.Slider(0.0, 1.0, 0.7, step = 0.1, label="Creativity Level (temperature):")
def generate_story(args):
prompt = f"""Write a {args[length_of_story]} story based on the following premise: \n
character_name: {args[character_name]} \n
character_type: {args[character_type]} \n
character_persona: {args[character_persona]} \n
character_location: {args[character_location]} \n
story_premise: {",".join(args[story_premise])} \n
If the story is "short", then make sure to have 5 chapters or else if it is "long" then 10 chapters.
Important point is that each chapter should be generated based on the premise given above.
First start by giving the book introduction, chapter introductions and then each chapter. It should also have a proper ending.
The book should have a prologue and an epilogue.
"""
response = model.generate_content(prompt, generation_config=genai.types.GenerationConfig(temperature=args[temperature]))
return [(prompt, response.text)]
# submit and show result
button = gr.Button("Submit")
chatbot = gr.Chatbot()
button.click(generate_story,
inputs={character_name, character_type, character_persona, character_location,
length_of_story, story_premise, temperature},
outputs=[chatbot])
demo.launch()

多模態分析
除了文字,在日常生活中我們還會用到多媒體數據來描述物件。 例如針對一個「雪景」,我們可以用文字記錄這個景色:「被靄靄白雪覆蓋的山坡與冷杉林」,也可以用照片記錄這個影像(下圖),或是用口說的方式記錄音訊。 這其實都是把「雪景」這個抽象概念提取重點,投射到不同維度適合的載體。 反過來我們也可以將文字、影像、聲音做為輸入,訓練一個模型去理解並配對這三種描述方式。

前面曾經說過,文字由 token 所構成,影像則由像素 (pixel) 所構成。 例如一個色彩深度 8bit 影像,代表可以用 28 = 256 種顏色來記錄色彩變化。 以灰階來說,就有 0-255 種深淺變化;如果放在彩色照片,就會對應 RGB 三個色彩通道 (channel),相當於 256 * 256 * 256 = 1678 萬種顏色變化。 一張解析度 1024 * 1024 的圖片,就會有超過 1 百萬個 pixels。
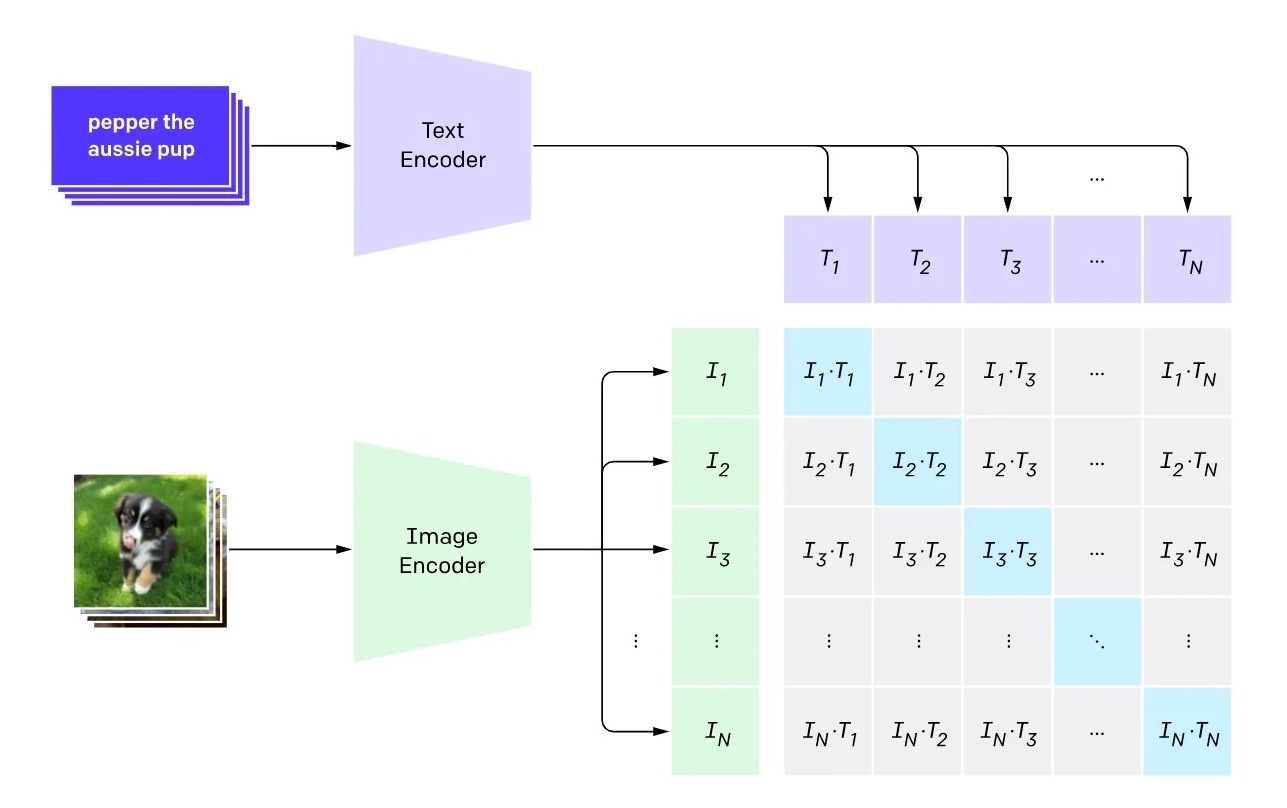
這些可以同時處理多媒體輸入或輸出的模型,又被稱作多模態模型 (multimodal model)。 以 OpenAI CLIP 為例, 我們可以用一個文字編碼器跟影像編碼器(或是傳統 CNN)分別讀取文字跟影像, 壓縮到對應的向量空間 (embedding space),然後用內積的方式計算兩個向量空間的匹配程度。 只要設計適當的 loss function 讓對應參數(藍色)越大越好、不對應的參數(灰色)越小越好,就可以將兩種表達方式在抽象空間內做連結。 訓練好多模態空間後,就可以用對應的解碼器去生成我們想要的內容。
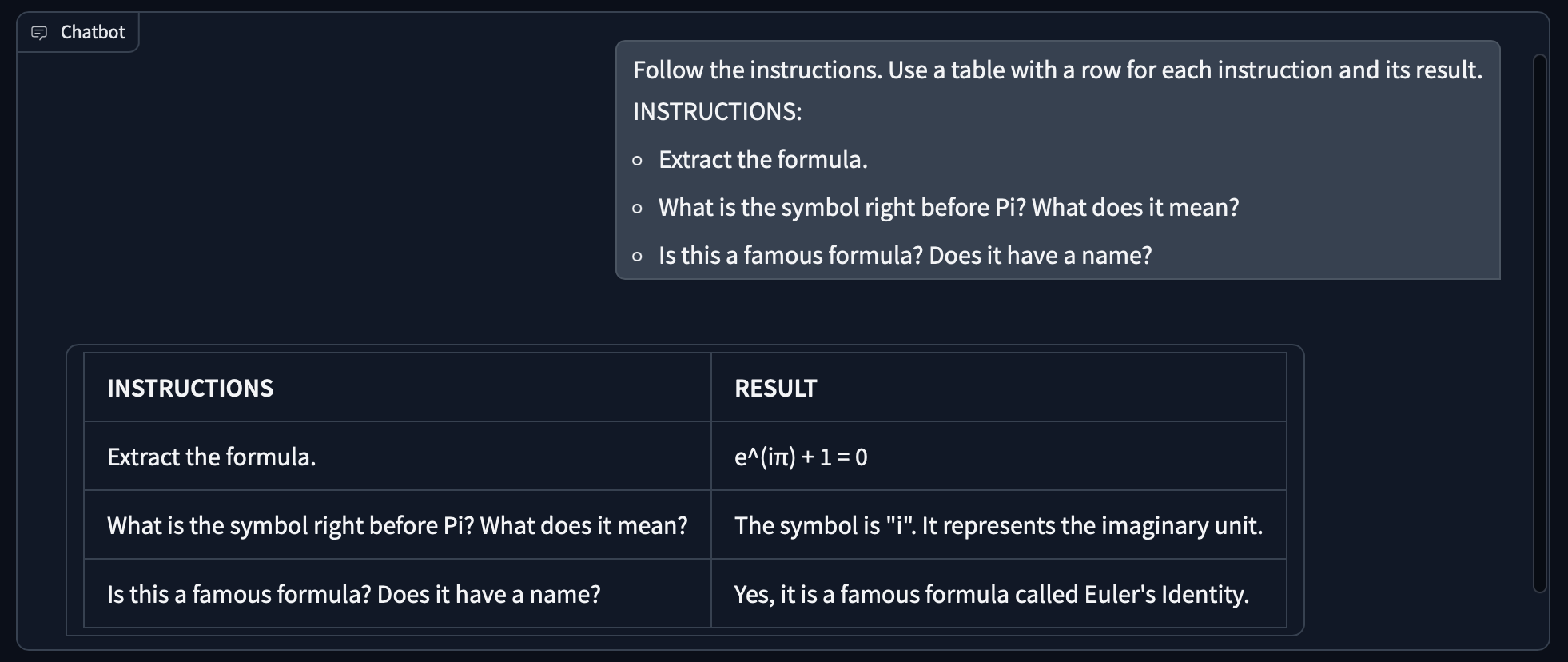
Gemini 作為一個 multimodal model,除了純文字也可以選擇輸入圖片和影片。 例如我準備一張數學公式的手寫圖片 math_equation.jpg(下圖),借助 LLM 多模態讀取資料與思考的能力,就可以進行數學公式的邏輯推理。 我們也可以將這些影像辨識的問題延伸到說明書讀取、最佳化佈局等應用。

file_path = 'math_equation.jpg'
def generate_answer(image, prompt):
prefix = """
Follow the instructions. Use a table with a row for each instruction and its result.
INSTRUCTIONS:
"""
prompt = prefix + prompt
response = model.generate_content([image, prompt], generation_config=genai.types.GenerationConfig())
return [(prompt, response.text)]
# construct the Gradio UI interface
with gr.Blocks() as demo:
gr.Markdown("# Math Reasoning\nUsing Gemini 1.5 Flash - Multimodal model")
image = gr.Image(file_path, type='pil')
prompt = gr.Textbox(label="Ask questions about the math equation as follows:", value="""
- Extract the formula.
- What is the symbol right before Pi? What does it mean?
- Is this a famous formula? Does it have a name?
""")
button = gr.Button("Submit")
chatbot = gr.Chatbot()
button.click(generate_answer, inputs=[image, prompt], outputs=[chatbot])
demo.launch()
至於影片,則可以看作無數張圖片的疊加。 我們常聽到的幀數 (frame per second, FPS) 就使指每秒幾張圖片,例如 60fps 代表一秒鐘有 60 張圖片掃過去。 越高的幀數會讓影片看起來更加流暢,但檔案也會隨之變得更大。 Gemini 目前支援最高 1hr 的影片輸入,但會將影片取樣壓縮至 1fps,對於高速變化的影片內容建議放慢速度來降低內容流失。
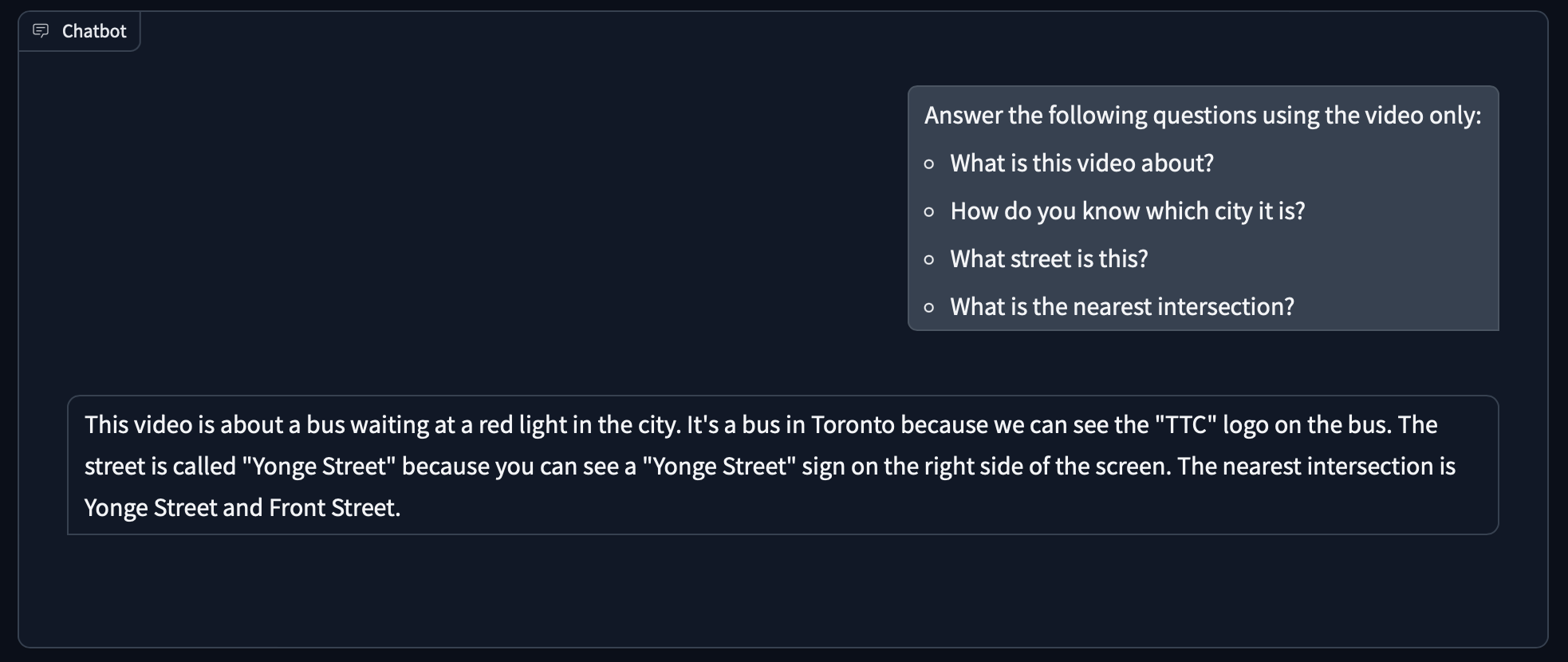
這裡我們使用一個路邊巴士與車輛的影片 bus.mp4,透過人工智慧強大的分析能力,不僅可以解讀影片內容,還可以從各種蛛絲馬跡(路標、車牌)推敲出影片拍攝的地點,非常厲害。
import time
file_path = 'bus.mp4'
def generate_location(video_path, prompt):
video = genai.upload_file(video_path)
# check whether the file is ready to be used
while video.state.name == "PROCESSING":
time.sleep(10)
video = genai.get_file(video.name)
if video.state.name == "FAILED":
raise ValueError(video.state.name)
prefix = "Answer the following questions using the video only:\n"
prompt = prefix + prompt
response = model.generate_content([video, prompt], generation_config=genai.types.GenerationConfig())
return [(prompt, response.text)]
# construct the Gradio UI interface
with gr.Blocks() as demo:
gr.Markdown("# Video Geolocation\nUsing Gemini 1.5 Flash - Multimodal model")
video_path = gr.Video(file_path)
prompt = gr.Textbox(label="Answer the following questions from the video:", value="""
- What is this video about?
- How do you know which city it is?
- What street is this?
- What is the nearest intersection?
""")
button = gr.Button("Submit")
chatbot = gr.Chatbot()
button.click(generate_location, inputs=[video_path, prompt], outputs=[chatbot])
demo.launch()
多媒體生成
最後我們來談談生成式 AI 如何產生圖片或音訊。 我們在前面已經提過文字生成是採用「文字接龍」的方式,將每次輸出的內容與輸入串接起來,預測下一次輸出的文字。 圖片或聲音的資訊既然已經序列化,當然也可以用接龍的方式來預測。 事實上早在 2016 年 Google WaveNet 就使用這種技術來生成高品質的聲音資訊。
然而人們很快就發現一個問題,這樣運算太慢了! 對於一張解析度 1024 * 1024 的圖片,就有大約 1 百萬個 pixels 要運算,相當於叫 LLM 輸出一本紅樓夢(120回本)的量。 對於一個 22KHz 一分鐘的音訊,就要做 132 萬次接龍。 對於用過 ChatGPT 的人應該知道,光是生成幾百字就要等幾秒鐘。 如果為了產生幾秒鐘的聲音就要等幾小時,顯然不是一個很好的做法。
事實上,我們可以運用平行處理的方式,一口氣預測所有 pixels,獨立運作每個解碼器的運算與輸出。 這樣做的好處是非常快,缺點是無法保證像素的連貫性。 例如要生成一隻貓的圖片,有個解碼器想畫黑貓、有個解碼器想畫白貓,最後就會產生一張四不像又很糊的照片。
為了解決這個問題,我們通常會混合兩種預測模式。 先用接龍的方式產生一張包含構圖的低解析度照片,再用平行處理的方式快速增加照片的大小與解析度。 如此重複好幾次,由 8 * 8 到 16 * 16,最終變成一張 1024 * 1024 的照片。 每次只需要由原像素預測旁邊的像素長什麼樣子,就可以大大降低不同解碼器共識不足的問題。
運用類似的概念,我們也可由一張很糊充滿雜訊 (noise) 的照片,經過一次次預測逐漸變成我們想要的樣子,這就是大名鼎鼎的 Diffusion Model。 目前主流的影像生成模型或服務,不論是 DALL-E、Stable Diffusion、Midjourney,通通是採用這種方式。 推薦台大李宏毅教授在 2024 年開設的 GAI 課程 第 17、18 堂,對於圖片和影像如何生成有非常清楚的說明。
有了多模態的編碼、解碼能力,大型語言模型就可以從影片生成文字,也可以從文字生成影片。 下面是 OpenAI 的 Sora 模型, 只要透過簡單的 prompt 就可以產生效果非常出色的影片。
A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.
因為目前 Gemini API 還沒有提供影像生成的服務,所以這邊就不實作應用程式了。 若想實際體驗,可以自行去試用 OpenAI 的 DALL-E 或 Sora。 目前 ChatGPT 每天也有兩次免費生成圖片的機會,有興趣的人不妨可以試試看。
Next: LLM 二部曲: Prompting and Alignment
Footnotes
Shakked Noy, Whitney Zhang, "Experimental evidence on the productivity effects of generative artificial intelligence." Science 381.6654, pp187-192, 2023. ↩
Ashish Vaswani, Noam Shazeer, Niki Parmar, et al., "Attention is all you need." Advances in Neural Information Processing Systems, 2017. ↩
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805, 2018. ↩
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, "Improving language understanding by generative pre-training." 2018. ↩
Mike Lewis, Yinhan Liu, Naman Goyal, et al., "Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension." arXiv preprint arXiv:1910.13461, 2019. ↩
Alec Radford, Jong W. Kim, Chris Hallacy, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021. ↩