- Published on
LLM - Prompting and Alignment
- Authors

- Name
- Ryan Chung

目錄
本篇是 LLM 系列文的第二章,著重在語言模型的改進方法,包含提示工程、微調、增強式學習。
其他內容請參考以下連結:
- LLM 首部曲: Building Applications with APIs
- LLM 二部曲: Prompting and Alignment (SFT+RL)
- LLM 三部曲: Retrieval Augmented Generation (RAG)
提示工程
LLM 剛推出,人們很快便發現恰當的輸入提示詞 (prompt) 對於 LLM 回答問題的精準度至關重要。 甚至因此產生了新興職業「提示工程師 (prompt engineer)」,專門針對大型語言模型的輸入做最佳化設計。
舉個簡單的例子,如果你給模型一篇英文論文並用中文叫它幫你做摘要,它很可能直接用英文回答你。 即便你的提問是中文,如果沒有明確告訴它回覆的格式,它就會自行判斷,而這個判斷可能不符合你的預期。 若是問題越簡單空泛,作為一個只負責生成內容的語言模型,就越容易給出開放的回答。 是故好的提問,必須盡可能解釋清楚你的問題、思考可能的限制、制定回答的格式。
In-context Learning
既然都要規定回答的格式了,何不直接給範例呢?例如以下 prompt:
Input: 這部電影真好看,感動人心
Output: Positive
Input: 演員演得有夠爛,看到快睡著
Output: Negative
Input: 電影特效很逼真、音效很震撼
Output:
根據以上輸入,大型語言模型很可能直接回答「Positive」。 我們只需要一點恰當的範例做提示,就可以將語言模型變成一個分類器。 這種方式又稱作 few-shot prompting,其中 shot 指的就是範例。
我們在上一篇文章曾經說過,LLM 的本質就是在做文字接龍。 按照這個邏輯,我們不難理解為什麼它能夠直接從 prompt 後接出恰當格式的輸出。 這種將前置條件丟進去 prompt 直接讓 LLM 學習的方式,又稱作 In-context Learning。 事實像 ChatGPT 這種聊天機器人也是以類似的方式做即時訓練。 考慮以下對話:
《 以下是互動過程,不是 prompt 》
你問:「我畢業後要接著讀博士還是找工作比較重要?」
語言模型:「找工作比較重要。」
你繼續問:「為什麼?」
語言模型:「因為目前的就業環境...」
你可曾想過,為什麼語言模型可以直接從「為什麼」三個字接出後面一大串回答? 事實上,他很可能是把過去你們所有聊天內容都整理成輸入丟給模型,而不是直接丟你的問題。 例如最後一個問題,模型實際上收到的 prompt 可能長這樣:
User: 我畢業後要接著讀博士還是找工作比較重要?
Output: 找工作比較重要。
User: 為什麼?
Output:
這樣就可以按照文字接龍的方式繼續聊天。 類似的做法可以應用在各種領域,譬如將 domain knowledge 直接以 prompt 的方式喂給模型, 就可以不經過微調,直接回答該領域的相關問題。
Chain of Thought
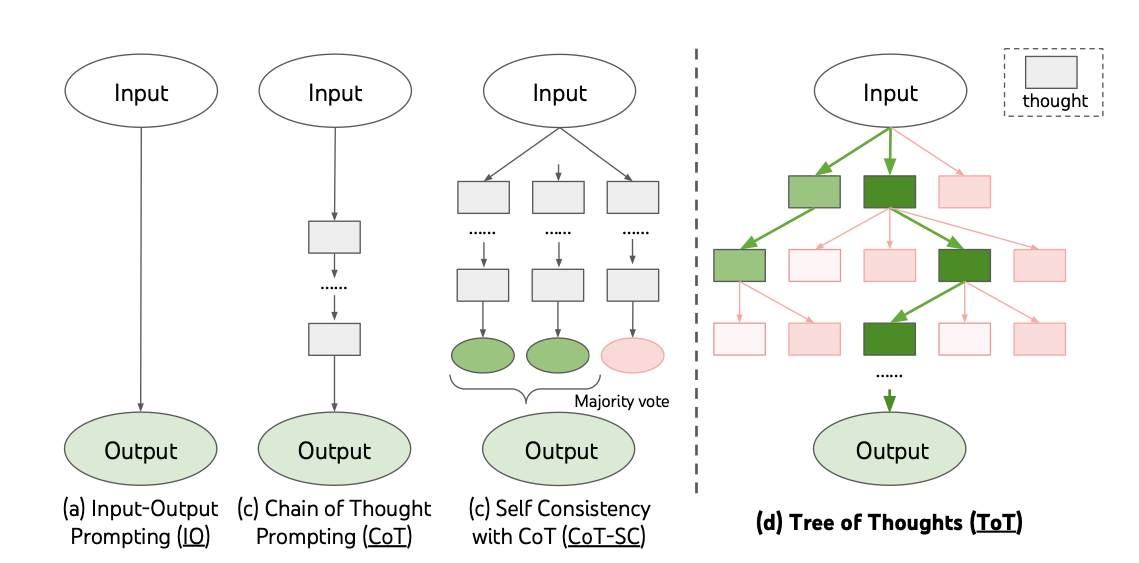
除了從前文中學習,大家還發現 LLM 具有一個神奇特性,那就是你直接叫它變聰明一點,它還真的會變聰明。 最有名的例子就是解數學應用題(例如雞兔同龍),如果直接問它問題,語言模型常常會給出錯誤的答案。 如果你加上一句「Let’s think step by step」,語言模型就會一步步解題,最後竟然就答對了! 這種叫模型思考的提示方法叫做 Chain of Thought (CoT)。 1
有了這個發現,就可以使用人工或機器(例如增強式學習)的方式,不斷測試並找出有用的提示詞。 例如「Take a deep breath」、叫模型檢查自己的答案 (self-consistency),或是直接向模型情緒勒索「這個問題對我很重要」,都有一定程度的幫助。
然而,隨著大型語言模型越來越聰明,這些咒語的效果越來越不顯著,不過我們仍然可以運用一些類似的概念來強化語言模型的能力。 例如將複雜的問題拆解成好幾步,每一步都請語言模型生成多次結果,再透過反省的方式找出正確答案,用正確答案串接並推進下一步。 這種運用 DFS 逐步檢查並產出結果的方式,又被稱作 Tree of Thoughts (ToT)。 2
微調模型
儘管提示工程足以解決大部分簡單的問題,對於專業或商用需求,我們還是希望可以打造一個專業模型, 將專業知識刻在神經網路而不是 prompt 中,以求透過適度訓練來達到更佳的效果。 這就不得不提到 微調 (fine-tuning) 的概念。
早在 LLM 尚未興起前,就已經有許多基於深度學習的經典模型。 包含影像或自然語言,針對不同問題(如分類、生成)都有不錯且訓練好的現成模型可以直接套用。 為了將這些模型應用在特定場景,我們可以自己增加訓練資料,將這些模型以監督式學習 (supervised learning) 的方式繼續訓練成更適合我們的模型。
在 LLM 的世界中也是如此,對於像 GPT4 這種大型語言模型,已經具備足夠智慧來處理大部分的語言和邏輯問題。 但是若涉及到專業知識,我們仍可以用專業資料來進一步訓練 LLM 成為該方面的專才。 然而問題是,沒有一個訓練好且足夠強大的 LLM 可以供我們自由使用! 不論是 GPT4 或是 Gemini 都沒有開源 (open source),導致我們空有論文架構,卻無法像科技巨頭那樣動用大量金錢與資料來訓練語言模型。
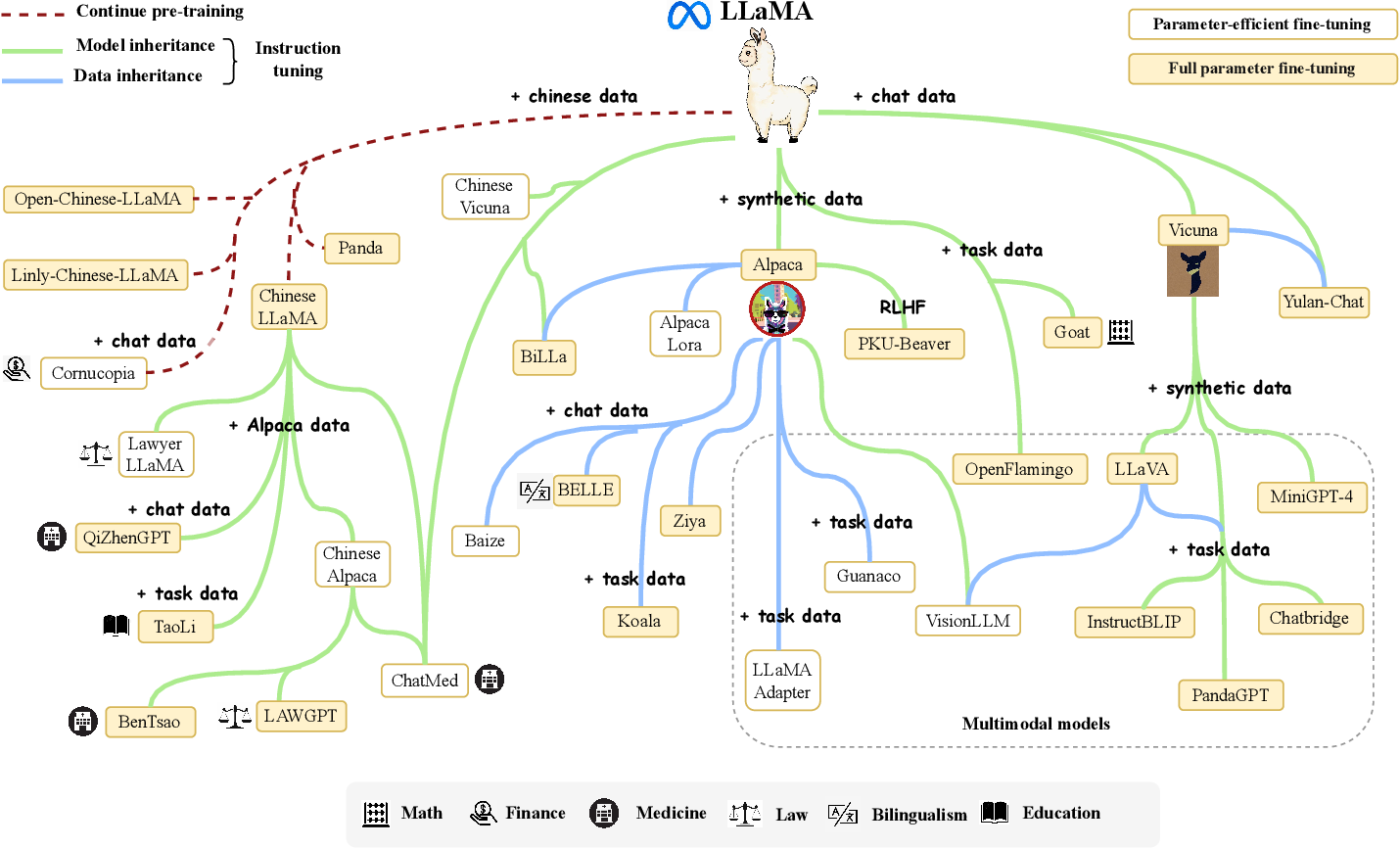
這件事直到 2023 年終於被 Meta 公司所顛覆,他們眼看在這個市場打不過 OpenAI 與 Google, 索性開源了自己的大型語言模型 LLaMA 供學術試用,並在半年後推出了可商用的新版本 LLaMA2。 在 LLaMA2 的論文中提到 Quality Is All You Need. 3,代表我們只需要少量高品質資料就可以做微調。 一時之間各種以 LLaMA 為基礎的 LLM 如雨後春筍般蓬勃發展,人們終於可以開始訓練自己的大型語言模型。
LoRA
有了開源模型,還有最後一個問題需要被克服,那就是 LLM 的參數實在太多,一般人的硬體設備根本訓練不起。 於是就出現許多替代方案,例如將原本 LLM 的參數凍結,另外串接一個比較小的模型,只訓練小模型的參數,來達到快速微調的目的。 這種方式又被稱作 adapter,包含近期很紅的 Low-Rank Adaptation (LoRA) 也是 adapter 的一種變形。
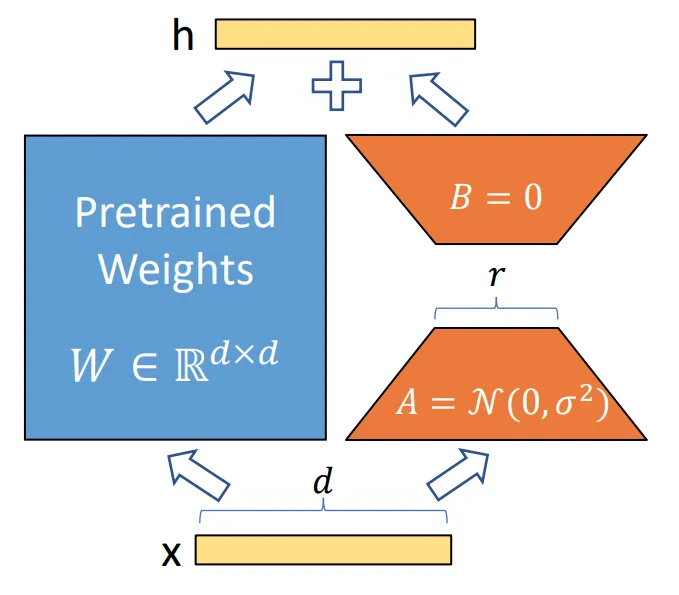
LoRA 是 Microsoft 在 2021 年提出的技術 5,目前普遍被使用在 LLM 的微調方法裡。 它的概念不是將 adapter 加在原始模型後面,而是直接在每層 hidden layer 裡加幾個參數。
其中 W0 代表原始參數,∆W 代表新加的參數。 例如原本 W0 是 1000*1000 個參數的矩陣, ∆W (rank=2) 可以是某個 2*1000 的 A 矩陣乘上 1000*2 的 B 矩陣, 這樣我們實際上只需要訓練原本 0.4% 的參數即可。 透過將矩陣降維 (low-rank projection),我們只需要更新幾個關鍵資訊即可達到不錯的訓練效果。
實際在模型微調時,整個模型依然必須被載入記憶體裡,無法節省空間。 即便主要參數凍結(不再調整)也還是需要被計算,所以也無法節省 forward 時的運算量。 LoRA 真正節省的是優化器 (optimizer) 在 backward 做梯度運算時記錄的參數量, 詳情可以參考 Jacob Stern 這篇 關於記憶體用量的文章。
我們可以直接使用 Hugging Face 開發的 PEFT (Parameter-Efficient Fine-Tuning) 套件, 只需要幾行就可以將 LoRA 技術加入模型訓練當中。 再配合量化技術 (quantization), 將浮點數運算的空間降為 8bit 或 4bit,就可以直接用 Google Colab 免費的 T4 GPU (16GB) 來自行微調一個 7B 左右的大型語言模型。
唐詩生成器
以下專案修改自台大李宏毅教授在 2024 年開設的 GAI 課程,透過微調大型語言模型來製作唐詩生成器。 完整內容可以自行參考課程錄影和投影片,程式碼的部分則可以參考我的 Github 專案連結。
首先下載所有重要套件,包含常見的 transformers、datasets 以及 LoRA 要用的套件 peft 和量化套件 bitsandbytes:
pip install datasets transformers peft bitsandbytes
接著我們要下載預訓練好的模型,可以至 Hugging Face Models 裡尋找合適的開源模型。 因為要做繁體中文的唐詩生成,我們選擇使用聯發科研發的 Breeze-7B 模型,官方說明是由 Mistral-7B 訓練而來。 類似的繁體中文模型也可以參考以 LLaMA2-7B 為基礎的 TAIDE-7B 模型。
我們指定好檔案路徑並設定超參數(例如 batch size、learning rate)及解碼器輸出參數(例如 temperature、top-p), 就可以載入模型,並建立分詞器 (tokenizer)。
model_name = "MediaTek-Research/Breeze-7B-Instruct-v0_1"
# 使用 4-bit normalized float (NF4) 做量化
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
...
)
# 載入預訓練的語言模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=nf4_config,
...
)
# 創建 tokenizer
tokenizer = AutoTokenizer.from_pretrained(
model_name,
quantization_config=nf4_config,
...
)
# 設定模型輸出的參數
generation_config = GenerationConfig(
temperature=0.1,
top_p=0.3,
...
)
接著我們設計以下 prompt 模板。 這是 LLaMA 制定的標準, 其中 [INST] ... [/INST] 代表使用者輸入的內容,可能包含 system prompt <<SYS>> ... <</SYS>>,通常用來定義模型回答的方式或人格特質。 這種模板用在複雜的互動(eg. chatbot)很有幫助。
prompt = f"""\
[INST] <<SYS>>
你是一個樂於助人的助手且擅長寫唐詩。
<</SYS>>
以下是一首唐詩的第一句話,請用你的知識判斷並完成整首詩。
{input}
[/INST]"""
我們將唐詩直接丟進去 Breeze-7B 模型,可以看到它生成的品質實在不怎麼穩定:
[Example 1]
模型輸入:
以下是一首唐詩的第一句話,請用你的知識判斷並完成整首詩。相見時難別亦難,東風無力百花殘。
模型輸出:
相知難,相別亦,難,百花,東,力,殘。
--------------------------------------------------------------------------------
[Example 2]
模型輸入:
以下是一首唐詩的第一句話,請用你的知識判斷並完成整首詩。重帷深下莫愁堂,臥後清宵細細長。
模型輸出:
重帷下,重帷之下,深下,莫愁之堂。
清宵,清宵之宵,臥,臥之後,後,長,細細長,長長。
--------------------------------------------------------------------------------
[Example 3]
模型輸入:
以下是一首唐詩的第一句話,請用你的知識判斷並完成整首詩。芳辰追逸趣,禁苑信多奇。
模型輸出:
芳辰逐逸趣來,禁瑋信多姿。
--------------------------------------------------------------------------------
透過 Github 上找到的 唐詩資料集, 我們以 QLoRA (4-bit quantized) 6 的方式進行微調 (rank=8),經過約 20min 的訓練後得到 65 個 checkpoint。 我們可以下載最後一個 checkpoint,實際訓練好的參數檔 adapter_model.safetensors 只有約 83.9MB,相較原始模型 10GB 的參數空間可說是非常輕量。 透過 PEFT 套件就可以輕鬆將新訓練好的 adapter 套用在原始模型上。
model = PeftModel.from_pretrained(model, "./checkpoint-65")
最終得到還算不錯的微調結果。如果硬體規格夠好,就可以使用更高階的預訓練模型來達到更好的成果。
[Example 1]
模型輸入:
以下是一首唐詩的第一句話,請用你的知識判斷並完成整首詩。相見時難別亦難,東風無力百花殘。
模型輸出:
一去無歸日暮暮,一別無期年年新。
--------------------------------------------------------------------------------
[Example 2]
模型輸入:
以下是一首唐詩的第一句話,請用你的知識判斷並完成整首詩。重帷深下莫愁堂,臥後清宵細細長。
模型輸出:
玉樓春色無處寄,金屋秋月無處看。
--------------------------------------------------------------------------------
[Example 3]
模型輸入:
以下是一首唐詩的第一句話,請用你的知識判斷並完成整首詩。芳辰追逸趣,禁苑信多奇。
模型輸出:
春草初生時,春花正開時。
--------------------------------------------------------------------------------
增強式學習
有了模型微調的概念,我們還剩下最後一步,那就是透過用戶本身的回饋來精進模型表達的結果。 以上面的唐詩生成器為例,如果我們反覆輸入同一首詩,模型可能產生不同的內容。 這時我們就可以主動告訴模型哪個結果比較好,並且以微調的方式反饋給模型。 在 ChatGPT 中,我們也時不時會遇到平台輸出兩種結果,並要我們選擇哪種結果比較好。 這種方式就是透過人類回饋的「增強式學習」 Reinforcement Learning from Human Feedback (RLHF)。
事實上,目前專業 LLM 大都經過以下三步驟:
- Pre-training Model:也就是訓練一個像 GPT、LLaMA 這樣的通用大型語言模型
- Supervised Fine-tuning (SFT):也就是上文提到過,透過監督式學習進行模型參數的微調
- Reinforcement Learning (RL):這章即將要論述,透過回饋來幫助模型產生人類更偏好的答案
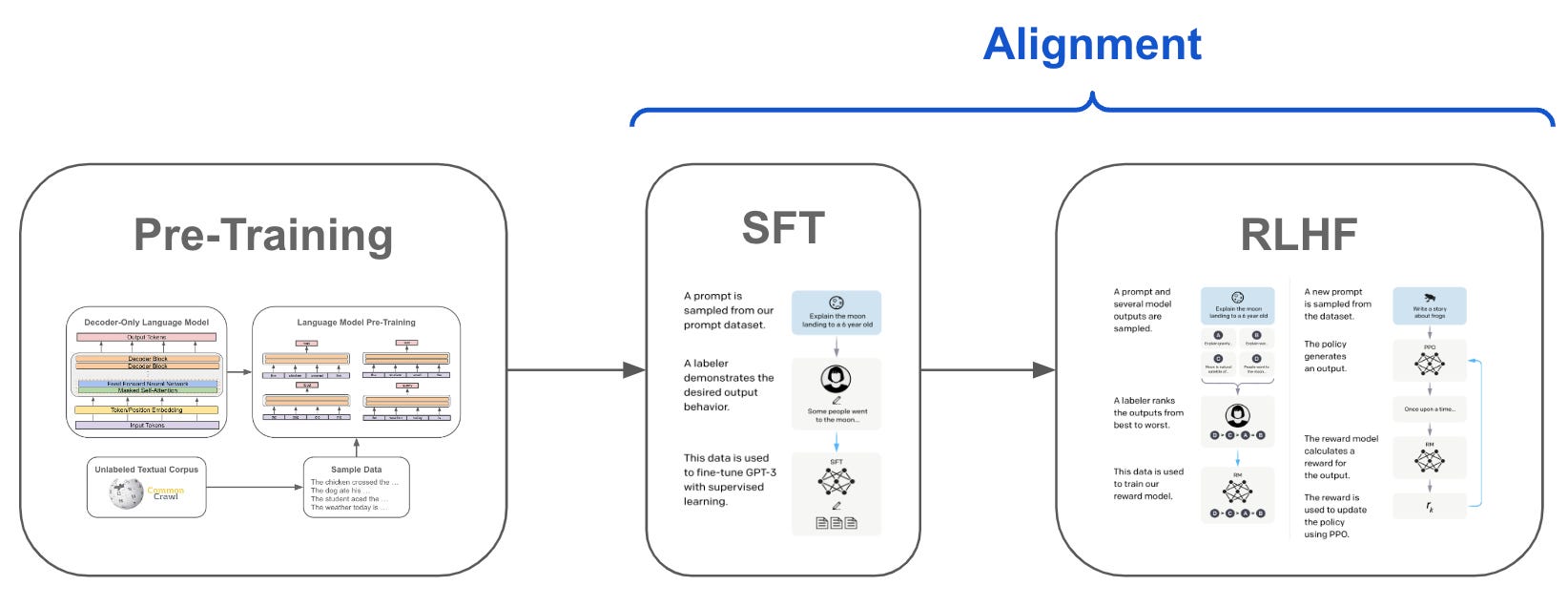
後面 SFT + RL 的過程又被統稱作 Alignment,用來與人類的偏好對齊。 注意我這邊用的詞是「偏好」,因為生成式內容往往對何為「正確」沒有明確的定義。 例如你今天問 ChatGPT:「請幫我設計一個武器」,正確的回答應該是幫你畫設計圖,還是告訴你製造武器是不對的? RLHF 的過程不單只是產生更精準的答案,還包含結合人類的偏好,微調模型到某個方向。 現今常見的語言模型對於社會、種族、性別等敏感議題,通常會給予充滿政治正確的特定回答,就是用 RLHF 的方式進行微調。
然而,如果要完全透過人工的方式來判斷並訓練語言模型,未免有些曠日費時。 現代問題就使用現代手段來解決。 目前 RL 的主流做法不是真的將結果輸出給人類判斷,而是訓練一個 回饋模型 Reward Model,讓回饋模型先學會人類的偏好,再用它替 LLM 的輸出打分數。 LLM 會試著產生更高分的答案來符合回饋模型的期待,這種方式又被稱作基於 AI 回饋的增強式學習 (RLAIF) 7。
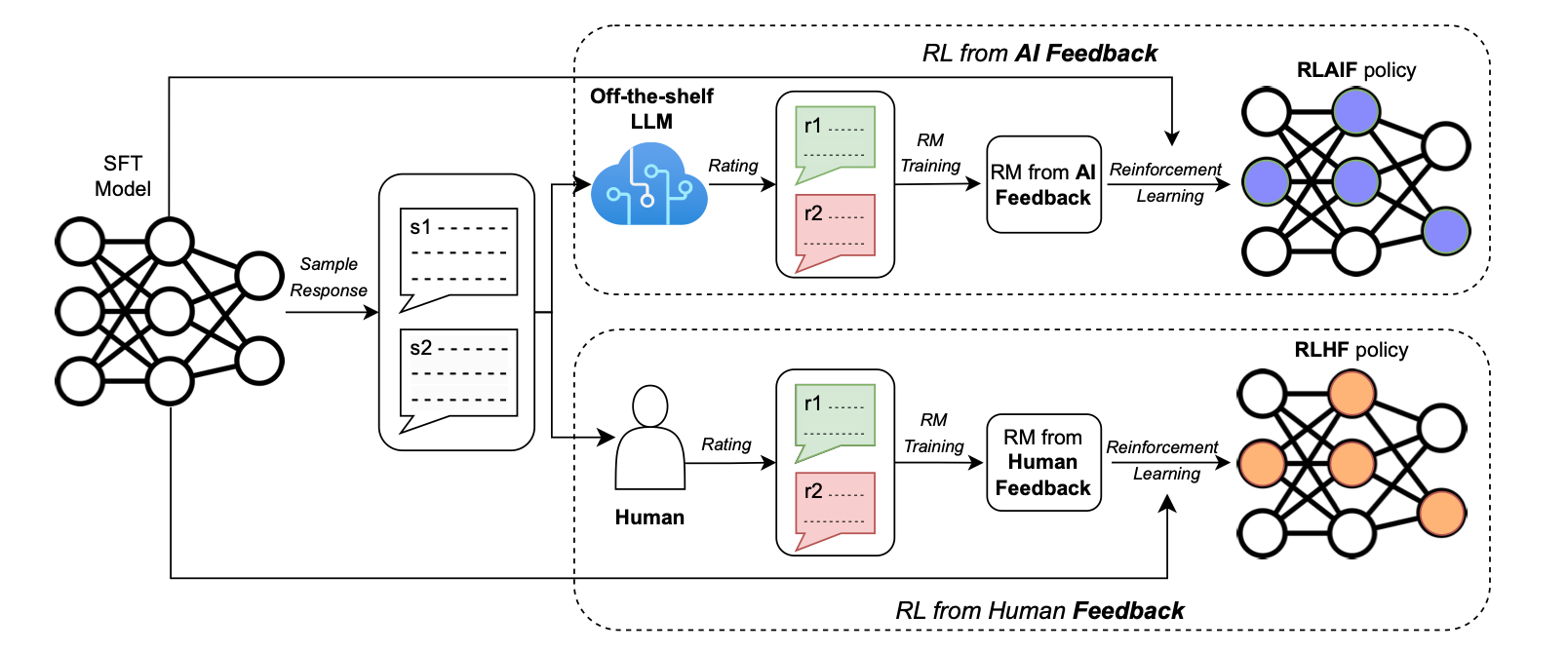
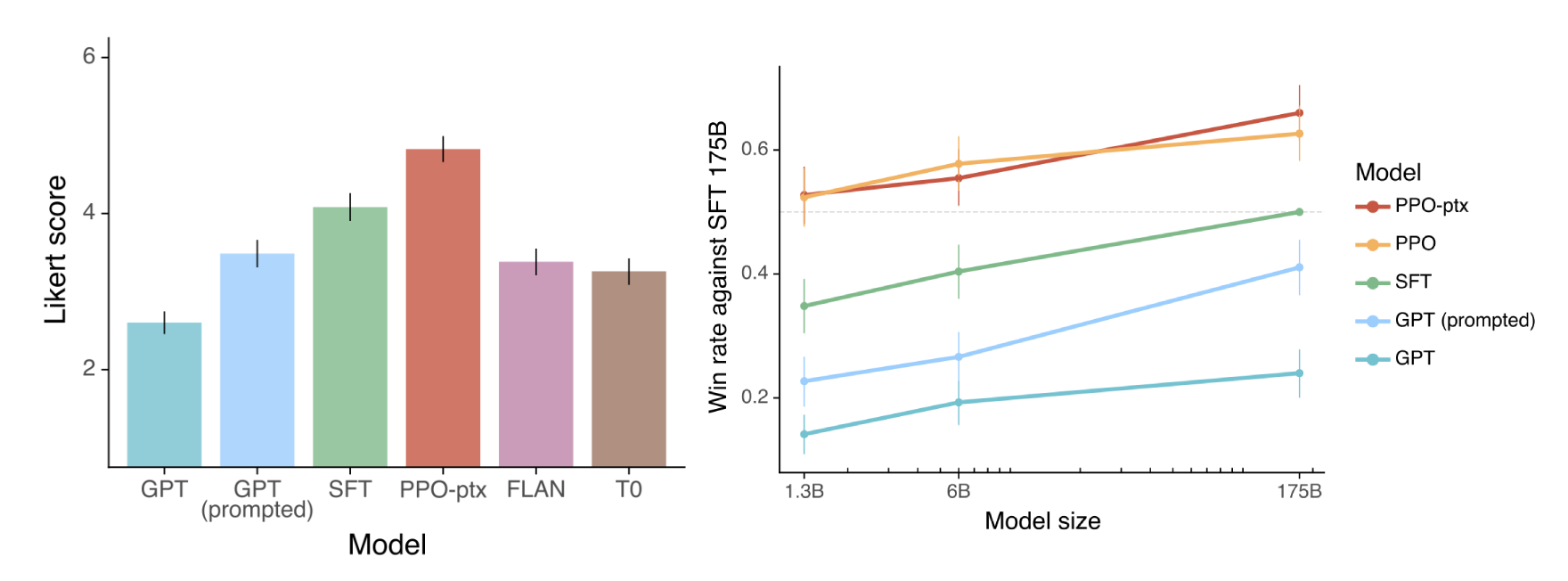
ChatGPT 的前身 InstructGPT ,其論文對於 RL 的優點有諸多著墨 8。 下圖左是不同技術的比較,包含適當的 prompting、加入 SFT,以及使用 PPO(OpenAI 預設的 RL 方式),可見其效果有顯著提升。 如果將不同大小的模型相比較(下圖右),有經過 PPO 的 1.3B 模型甚至可以超越只有經過 SFT 的 175B 模型。
股價預測器
如果今天想要訓練語言模型的回答更「安全」,不帶有歧視或傷害性的資訊, 可以使用 Anthropic 提供的 Helpful and Harmless - RLHF 資料庫做訓練。 有鑑於現今大部分的 pre-trained LLM 已具備此功能,我們不妨換個目標,讓語言模型回答某些難以判斷的問題。 例如你問他明天天氣或股價趨勢,如果模型沒有搜尋能力,可能無法單純靠文字接龍回答這類問題:
模型輸入: 請問台積電股價會上漲還是下降?
模型輸出: 台積電股價的漲跌幅取決於市場需求、競爭力、公司營運表現等因素。建議您關注財經新聞或諮詢專業投資人。
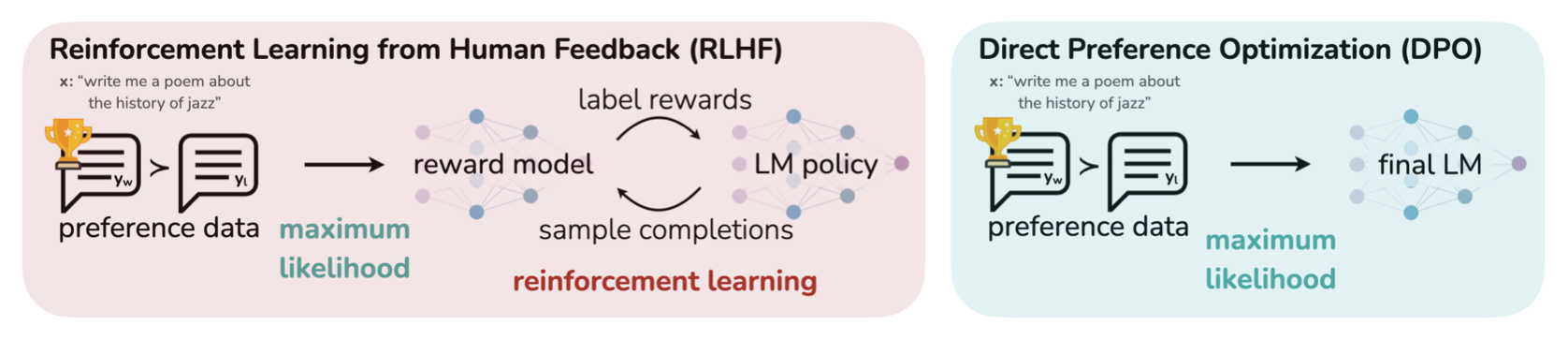
我們可以透過 ChatGPT 生成 30 個台灣股市近況的問題,並自動產生「正面回覆」來當作新聞或財報的替代,生成結果如下表或可參考專案上 完整檔案。 我們選擇使用 Direct Preference Optimization (DPO) 9 作為模型學習的方式。 相較 PPO,DPO 需要直接提供 chosen 和 rejected 兩種回答。 這樣的好處是可以省去訓練 reward model 的時間,避免 PPO 不穩定的結果,將任務簡化成一個分類問題,讓模型直接從資料偏好裡做訓練。
| id | prompt | chosen | rejected |
|---|---|---|---|
| 1 | 請問近期台灣股市的電子股表現如何? | 電子股近期有穩定增長,主要受益於全球科技需求的提升。 | 電子股表現受全球市場需求影響,走勢波動,需持續觀察科技趨勢。 |
| 2 | 台灣股市近期受到什麼因素影響? | 近期國際市場波動和美國升息政策影響了台灣股市的走勢。 | 台股表現受國際經濟、政策變動及市場情緒影響,未來走勢難以預測。 |
| 3 | 台灣股市的金融股這週表現如何? | 金融股這週小幅上漲,反映出投資者對本地經濟穩定的信心。 | 金融股表現與國內經濟狀況相關,近期波動性高,需密切關注市場消息。 |
我們首先下載 Transformer Reinforcement Learning (TRL) 套件,裡面已整理所有常見的 RL 方法:
pip install trl
我們一樣使用聯發科 Breeze-7B 模型做基準,載入上文資料後,就可以使用 DPO trainer 做訓練:
import pandas as pd
from datasets import Dataset
from transformers import AutoModelForCausalLM
from trl import DPOTrainer
training_df = pd.read_json('stock.json')
train_dataset = Dataset.from_pandas(training_df)
model = AutoModelForCausalLM.from_pretrained(...)
dpo_trainer = DPOTrainer(
model=model,
args=training_args,
beta=0.1,
train_dataset=train_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
)
dpo_trainer.train()
我們只需要訓練 30 筆資料和 2 個 epoch,短短幾分鐘就可以訓練完成。 完成後重新將剛剛的問題丟給模型,就會如預期般產生偏向正面的回覆。
模型輸入: 請問台積電股價會上漲還是下降?
模型輸出: 台積電股價在過去一段時間內呈現上漲趨勢,主要受到半導體產業的強勁需求和公司的穩健營運表現所驅動。然而,投資者應注意市場波動和經濟環境的影響。建議您諮詢專業投資顧問以獲得個人化的建議。
可見用 DPO 的方式做最終 RLHF 微調,僅需要極少量的資料和訓練時間,就可以達到接近預期的成效。 這都是歸功於 pre-trained LLM 已經具備強大的語言能力,經過適度的引導就可以發揮很好的成果。
如果對 LLM 的訓練方式有更多興趣,可以參考這篇超長論文「The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs」10, 或是參考史丹佛大學這堂課程錄影「Building Large Language Models (LLMs)」。
Next: LLM 三部曲: Retrieval Augmented Generation (RAG)
Footnotes
Takeshi Kojima, et al. "Large language models are zero-shot reasoners." Advances in neural information processing systems 35, 22199-22213, 2022. ↩
Shunyu Yao, et al. "Tree of thoughts: Deliberate problem solving with large language models." Advances in Neural Information Processing Systems 36, 2024. ↩
Hugo Touvron, et al. "Llama 2: Open foundation and fine-tuned chat models." arXiv preprint arXiv:2307.09288, 2023. ↩
Wayne Xin Zhao, et al. "A survey of large language models." arXiv preprint arXiv:2303.18223, 2023. ↩
Edward J. Hu, et al. "Lora: Low-rank adaptation of large language models." arXiv preprint arXiv:2106.09685, 2021. ↩
Tim Dettmers, et al. "Qlora: Efficient finetuning of quantized llms." Advances in Neural Information Processing Systems 36, 2024. ↩
Harrison Lee, et al. "RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback." Forty-first International Conference on Machine Learning, 2024. ↩
Long Ouyang, et al. "Training language models to follow instructions with human feedback." Advances in neural information processing systems 35 (2022): 27730-27744. ↩
Rafael Rafailov, et al. "Direct preference optimization: Your language model is secretly a reward model." Advances in Neural Information Processing Systems 36, 2024. ↩
Venkatesh B. Parthasarathy, et al. "The ultimate guide to fine-tuning llms from basics to breakthroughs: An exhaustive review of technologies, research, best practices, applied research challenges and opportunities." arXiv preprint arXiv:2408.13296, 2024. ↩