- Published on
COVID-19 Image Recognition Application
- Authors

- Name
- Ryan Chung
簡介
過去幾年以來,嚴重特殊傳染性肺炎 (Coronavirus disease 2019, COVID-19) 肆虐全球,全球累積破億個確診病例、數百萬名患者死亡,成為人類歷史上致死人數最多的流行病之一。 這波疫情重創無數的產業和活動,針對 COVID-19 的相關研究也持續發展中。 1
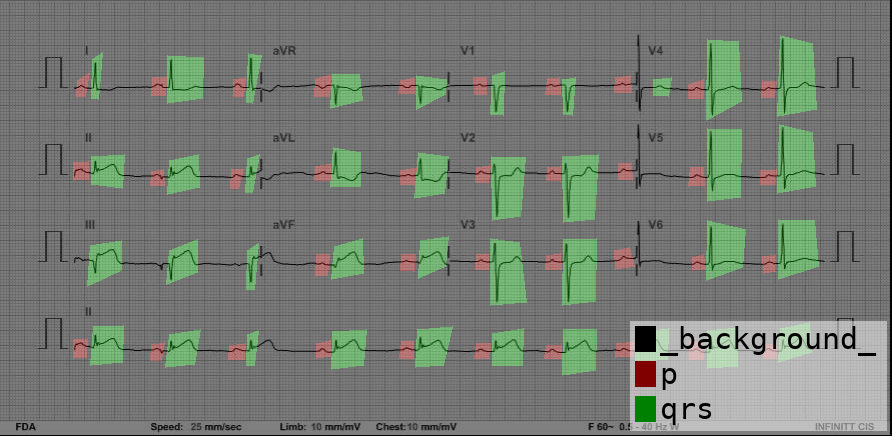
其中,基於深度學習的影像辨識在醫療領域一直有著重要的應用,例如透過人工標記的方式在心電圖 (ECG) 上註明 PQRS 波段位置,就可以讓模型學會判讀波形,進一步計算心律或分析疾病特徵。
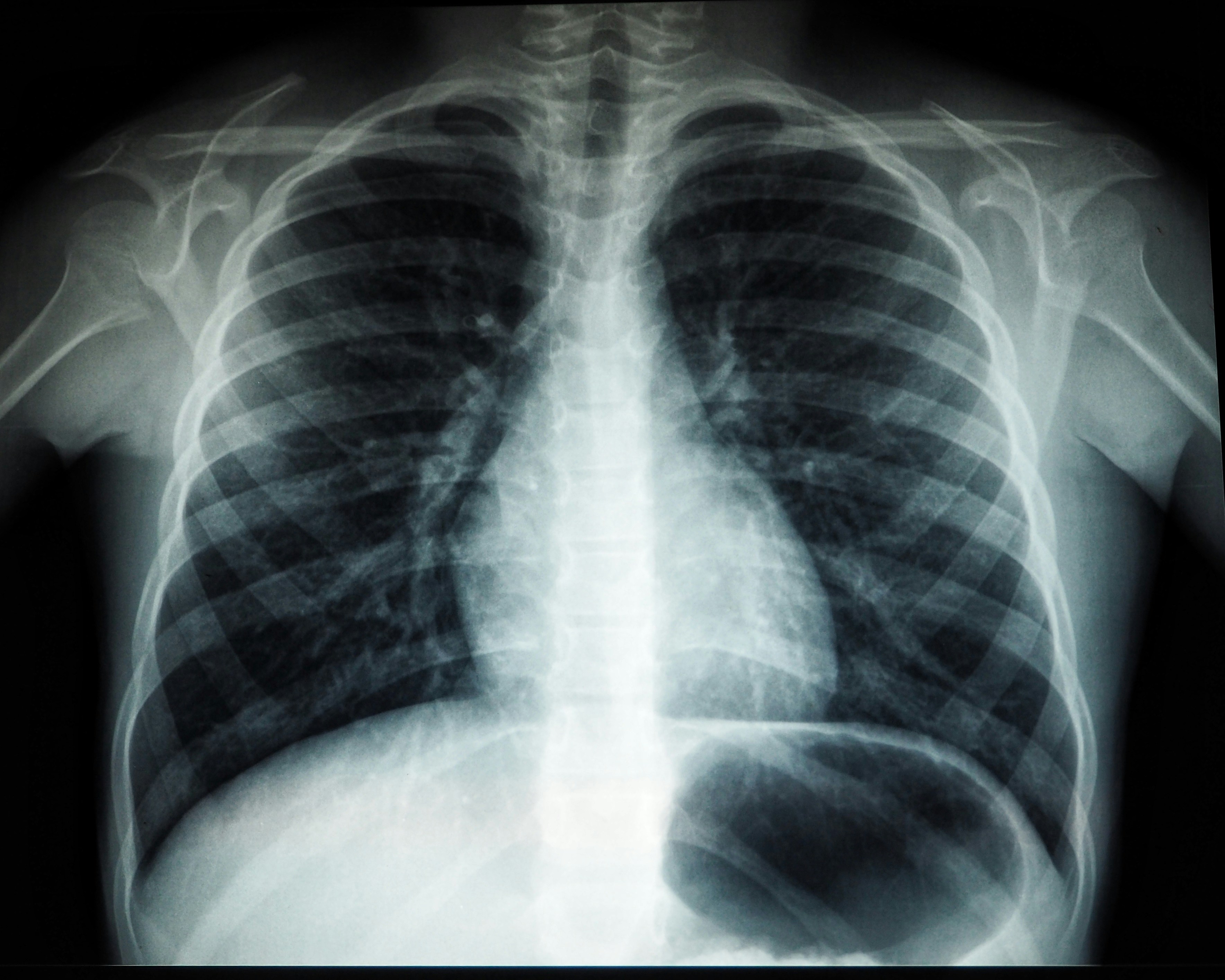
同樣的方式可以應用在各種醫療影像上,例如 X 光片、眼底攝影 (OCT)、超音波、腦波圖 (EGG)、磁振造影 (MRI)、病理組織切片等。 在過往案例中,比較常見使用胸部 X 光片來判斷 COVID-19 的患者,如果採用二分法,其難點在於 COVID-19 的影像不容易跟其他肺炎做區分。 有鑑於此,能夠正確標記不同疾病的專業資料集非常重要。
在這個專案中,我們試著利用影像辨識的方式從肺部電腦斷層 Computed Tomography (CT) scan 來區分 COVID-19 的患者。 此外,我們也嘗試使用 YOLO 模型來偵測口罩配戴的效果,如果對這個專案有興趣,請直接參考 Part2。
資料集介紹
COVID-Net is a global open source, open access initiative dedicated to accelerating advancement in machine learning to aid front-line healthcare workers and clinical institutions around the world fighting the continuing pandemic.
COVID-Net 2 是近年建立的開源資料庫,擁有非常多 COVID-19 患者的醫療影像紀錄,主要包含以下三種:
- Chest x-rays: 30,882 images across 17,036 patients
- Chest CT: 201,103 CT slices from 4,501 patients
- Chest point-of-care ultrasound: 29,651 POCUS images
除了簡單的二分法,COVID-Net 的資料能夠正確區分 COVID-19 與其他肺炎的差異,對於深度學習的訓練相當有幫助。
模型分析
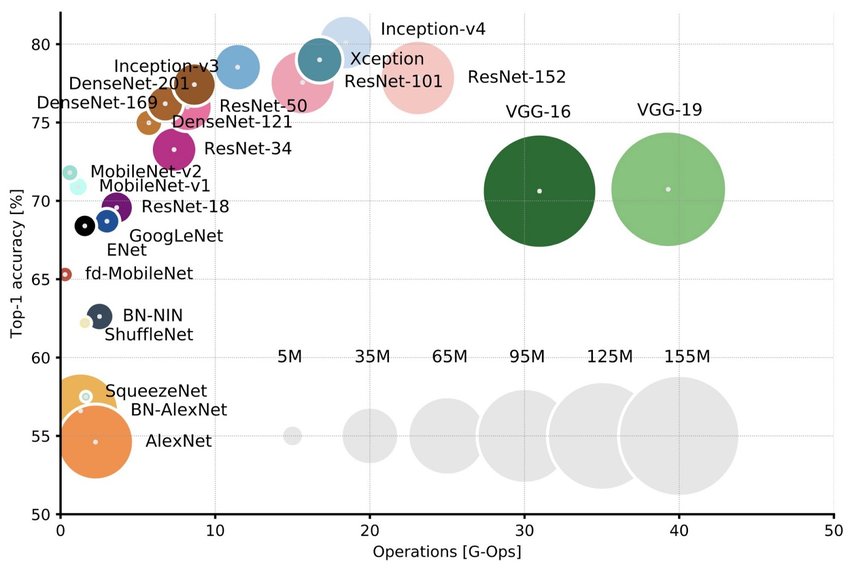
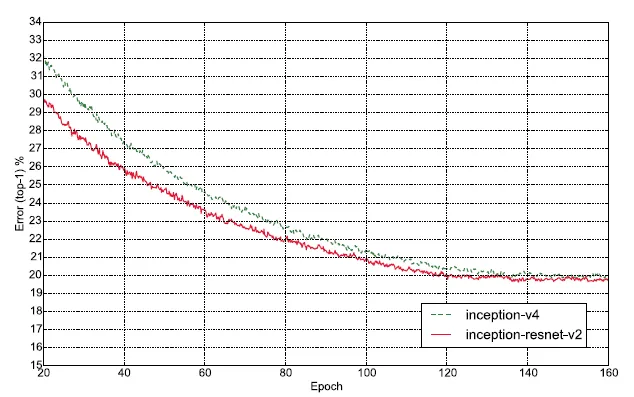
本次實驗我們的模型使用 InceptionResNetV2,它是這篇論文「Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, Christian Szegedy」提出的模型 3 ,由 GoogLeNet (Inception-v1) 演化而來,並結合 ResNet 的部分優勢。 從下圖中我們可以看到從 Inception-v1 到 v4 的 top-1 準確率,可見 Inception-v4 優於 ResNet 4 。InceptionResNetV2 的收斂速度比起 Inception-v4 要快,準確率也稍微好一些。
Residual Inception Block 的概念是通過增加一條直連通路來加快 Inception module 的訓練速度。 InceptionResNetV2 則引用了原本 Inception v4 的架構,但是設計了三個新的 Inception-ResNet Block A、B、C,期望透過加深網路來獲得更好的模型準確度。 此外,在中間加入 Reduction Layer,可以降低特徵圖的尺寸,避免特徵信息流失。 最終模型架構如下圖所示。
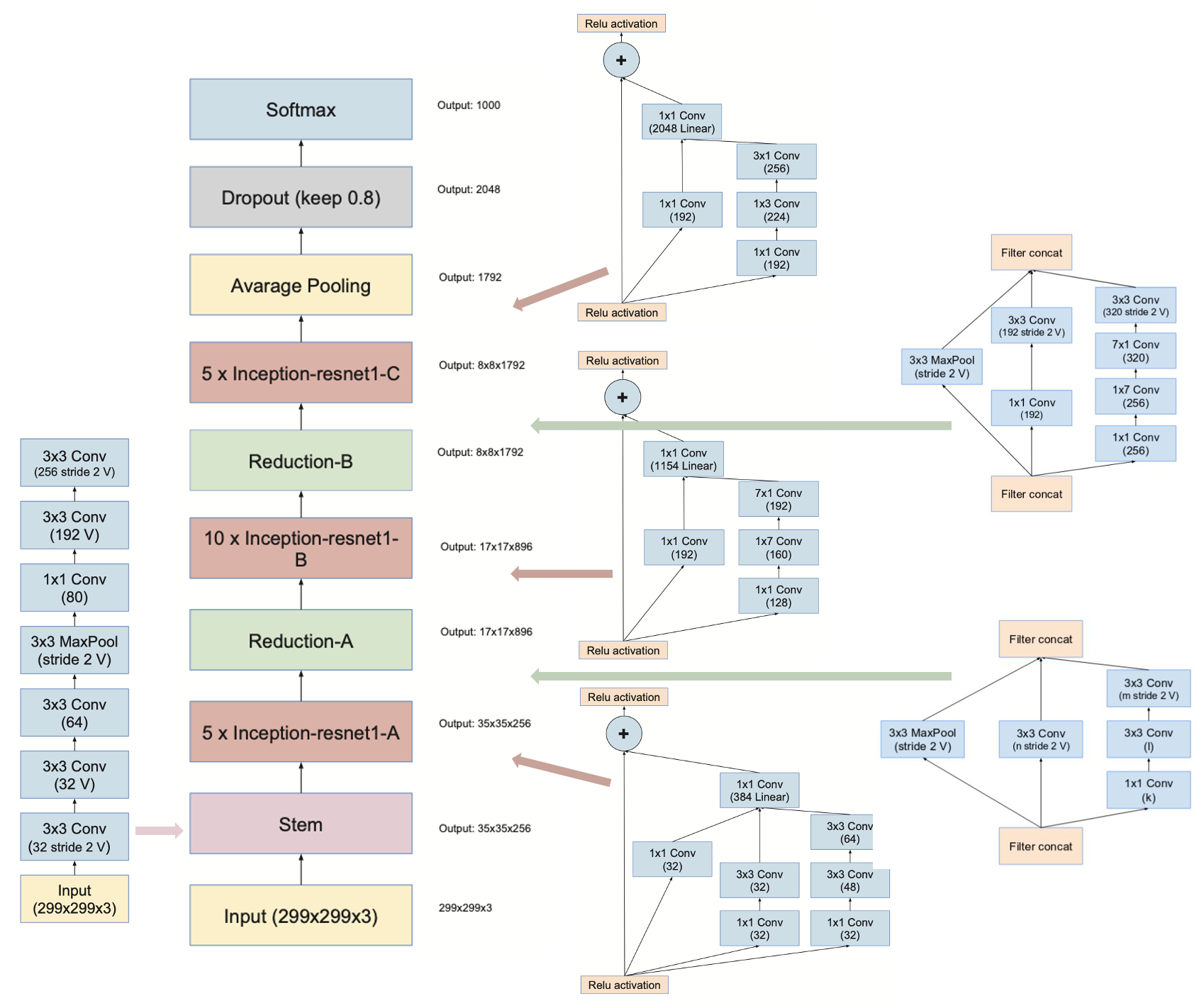
除了原本的 InceptionResNetV2,我們在輸出層額外加上一層 Global Average Pooling 2D 與七層 Dense,將輸出參數從 1024 慢慢收斂到 3,即我們稍後要介紹的三個肺部 CT 種類。 模型編譯的部分,我們的 optimizer 選擇使用 Adam (learning rate 0.001),loss function 選擇 categorical crossentropy。 最終模型的參數如下表所示。
| Total params | Trainable params | Non-trainable params |
|---|---|---|
| 56,618,051 | 56,550,515 | 67,536 |
資料前處理
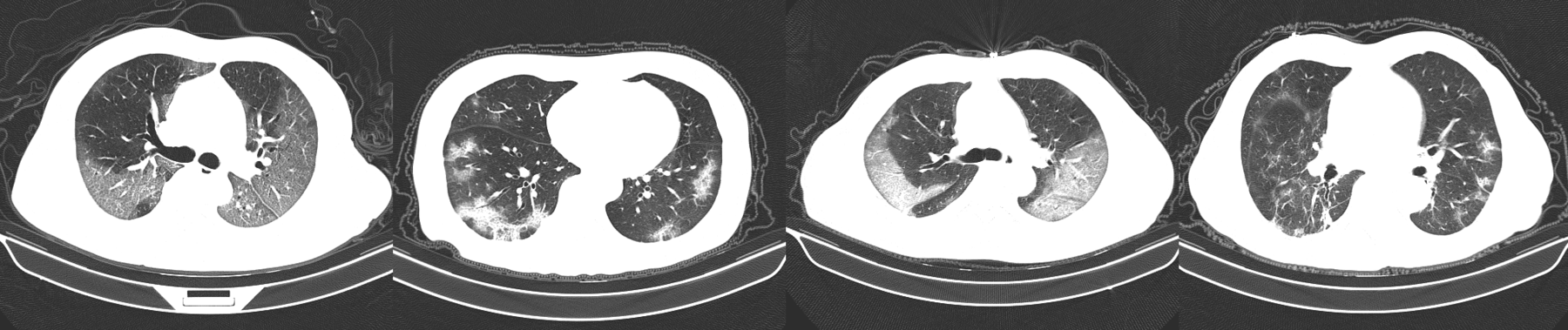
本次實驗下載自 COVID-Net 上的 Benchmark Dataset,即 Kaggle 上的資料集 COVID x CT-2 5,從 3,745 個患者整理了 194,922 張 CT 照片,每張再進一步標記成三類:Normal = 0, Pneumonia = 1, COVID-19 = 2。 前處理的部分,為了運算速度的考量,所有照片統一 resize 至 128*128 pixles, 並將每一個 pixel 的數值標準化至 0~1 range,同時將照片 label 作 one-hot encoding。
總照片數量只取其中 6000 張,Training + Validation 與 Testing 的比例是 8:2, Training 與 Validation 的比例也是 8:2,所以最終照片數量會如下表所示:
| Training | Validation | Testing |
|---|---|---|
| 3,840 | 960 | 1,200 |
因為不同病人有數量不一的 CT 照,故病人所佔照片的比例也會影響模型訓練與測試的結果。 我們將資料獲取的方式分成三類,一種是按順序取各 label 前 2000 張圖片 (人數不平衡); 一種是盡可能獲取所有病人資料,但是各 label 的人數不平衡; 一種是盡可能增加病人數量,但是各 label 的病人數需相同。 結果如下表所示:
| 取法一 病人數不均衡 | 取法二 病人數最大化 | 取法三 病人數均衡 |
|---|---|---|
| Covid 取 40 人 ( 1 人 50 張 ) Normal 取 5 人 ( 1 人 400 張 ) Pneumonia 取 50 人 ( 1 人 40 張 ) | Covid 取 2000 人 ( 1 人 1 張 ) Normal 取 500 人 ( 1 人 4 張 ) Pneumonia 取 666 人 ( 1 人 3 張 ) | Covid 取 500 人 ( 1 人 4 張 ) Normal 取 500 人 ( 1 人 4 張 ) Pneumonia 取 500 人 ( 1 人 4 張 ) |
除了病人資料的取法不同外,我們額外做了 data augmentation,方法是隨機將照片作 random rotate (-15 ~ 15 degree),以此來比較 augmentation 前後的差別。
實驗過程
實驗一
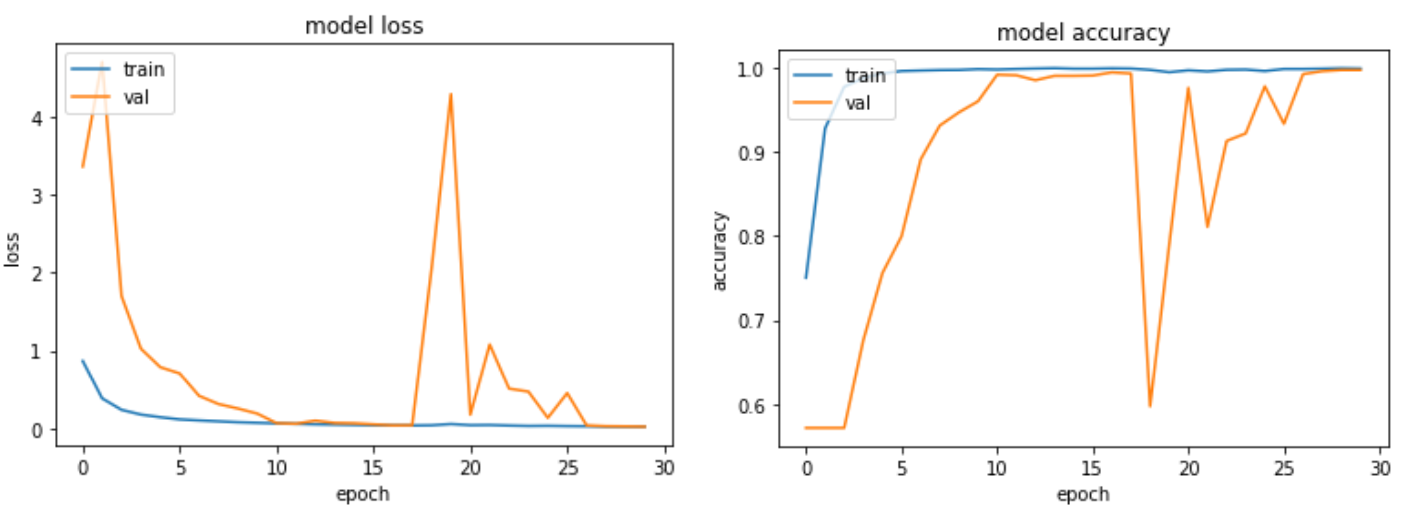
每個 label 照片取到 2000 張,人數不平衡 + 無 data augmentation
Train on 3840 samples, validate on 960 samples, test on 1200 samples
- Label covid 取 40 人 ( 1 人 50 張 )
- Label normal 取 5 人 ( 1 人 400 張 )
- Label Pneumonia 取 50 人 ( 1 人 40 張 )
訓練過程與測試結果:
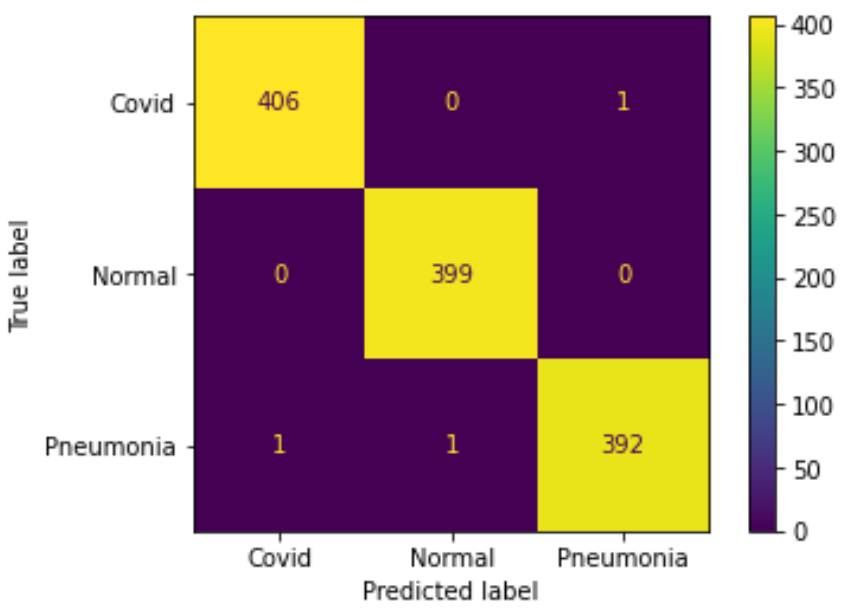
實驗二
每個 label 照片取到 2000 張,人數不平衡 + 有 data augmentation (數量 1:1 加入隨機旋轉圖片)
Train on 7680 samples, validate on 1920 samples, test on 2400 samples
- Label covid 取 40 人 ( 1 人 50 張 )
- Label normal 取 5 人 ( 1 人 400 張 )
- Label Pneumonia 取 50 人 ( 1 人 40 張 )
訓練過程與測試結果:
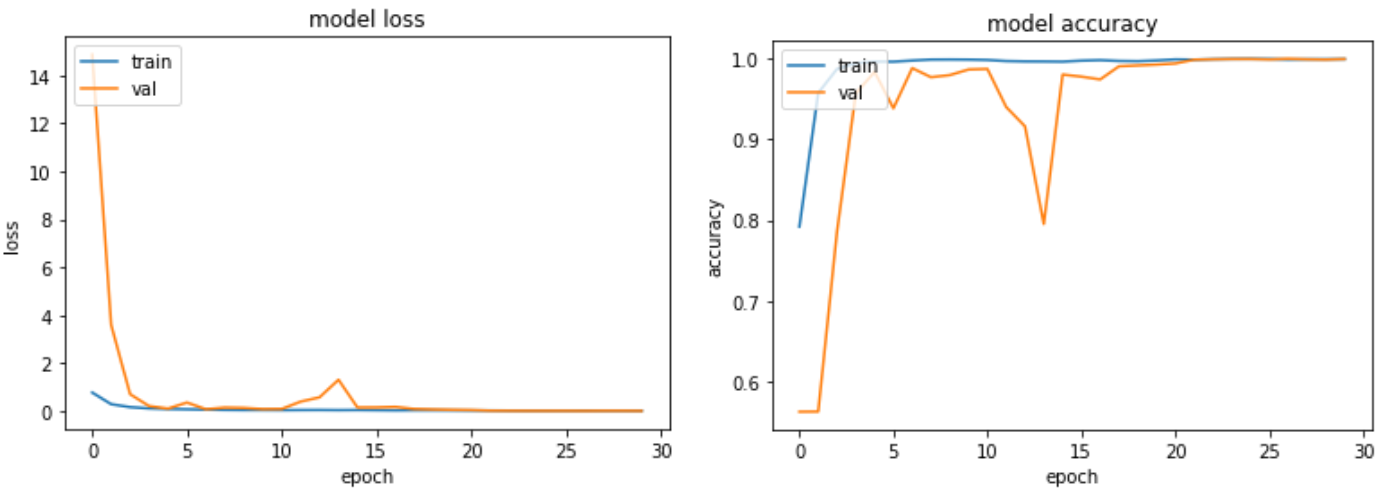
實驗三
盡可能取全部人數,人數不平衡 + 無 data augmentation
Train on 3840 samples, validate on 960 samples, test on 1200 samples
- Label covid 取 2000 人 ( 1 人 1 張 )
- Label normal 取 500 人 ( 1 人 4 張 )
- Label Pneumonia 取 666 人 ( 1 人 3 張 )
訓練過程與測試結果:
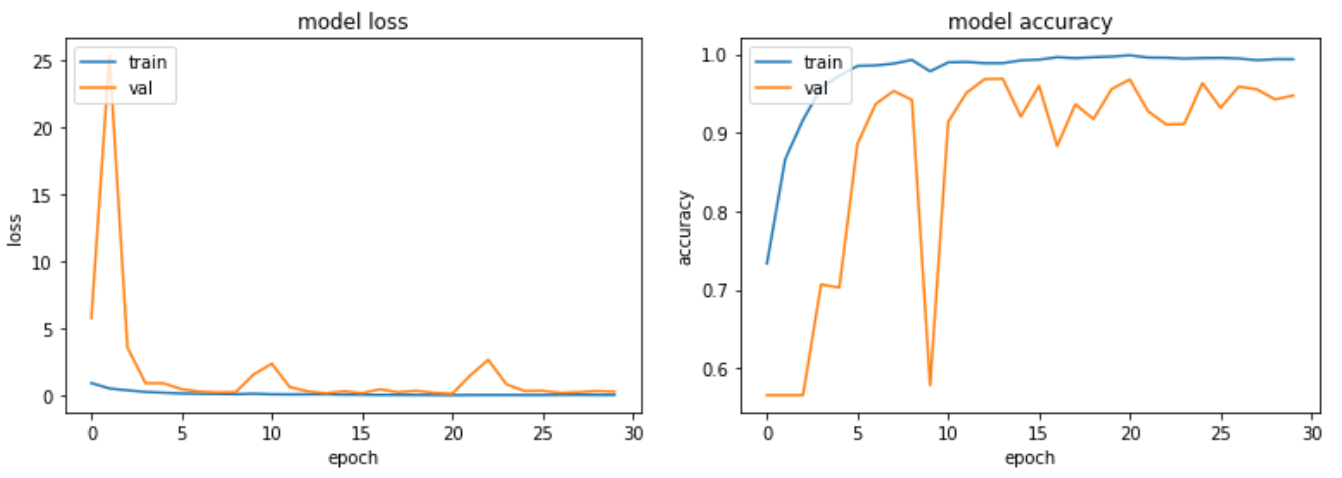
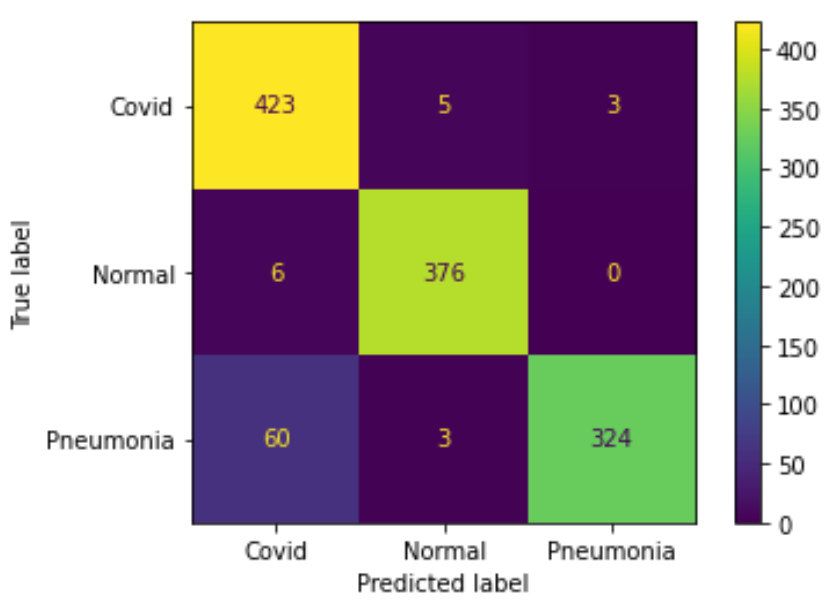
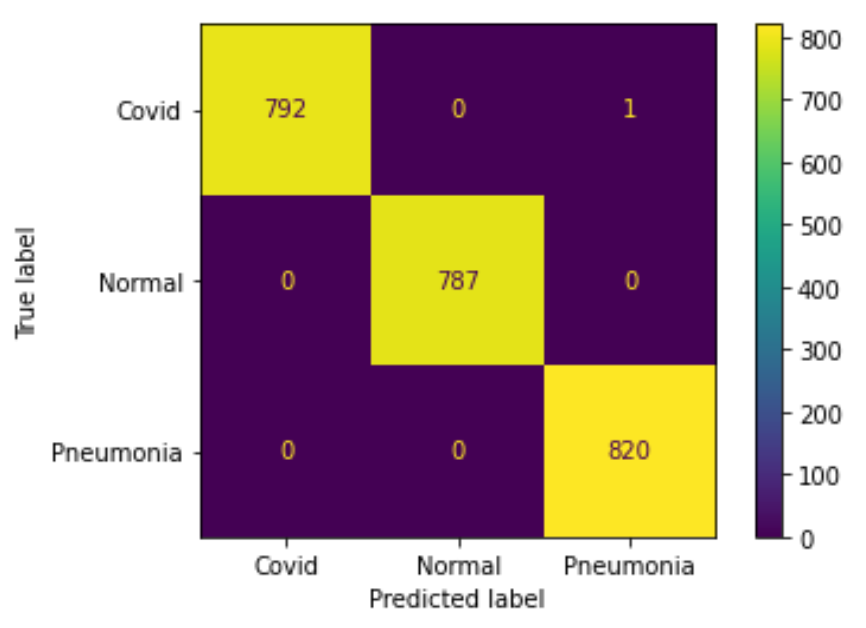
實驗四
盡可能取全部人數,人數不平衡 + 有 data augmentation (數量 1:1 加入隨機旋轉圖片)
Train on 7680 samples, validate on 1920 samples, test on 2400 samples
- Label covid 取 2000 人 ( 1 人 1 張 )
- Label normal 取 500 人 ( 1 人 4 張 )
- Label Pneumonia 取 666 人 ( 1 人 3 張 )
訓練過程與測試結果:
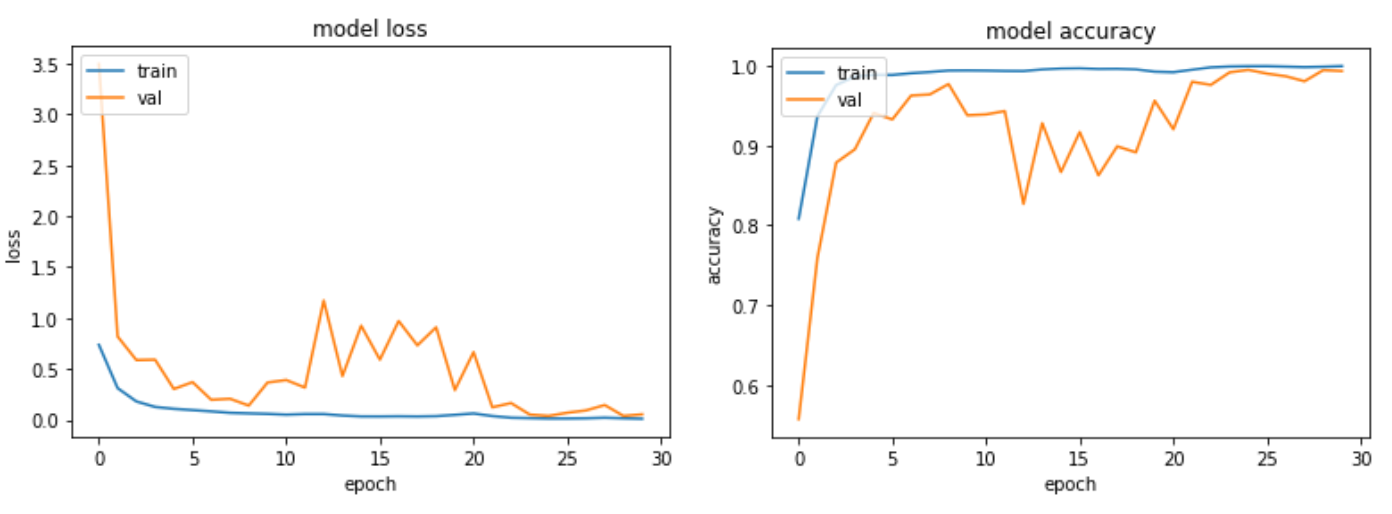
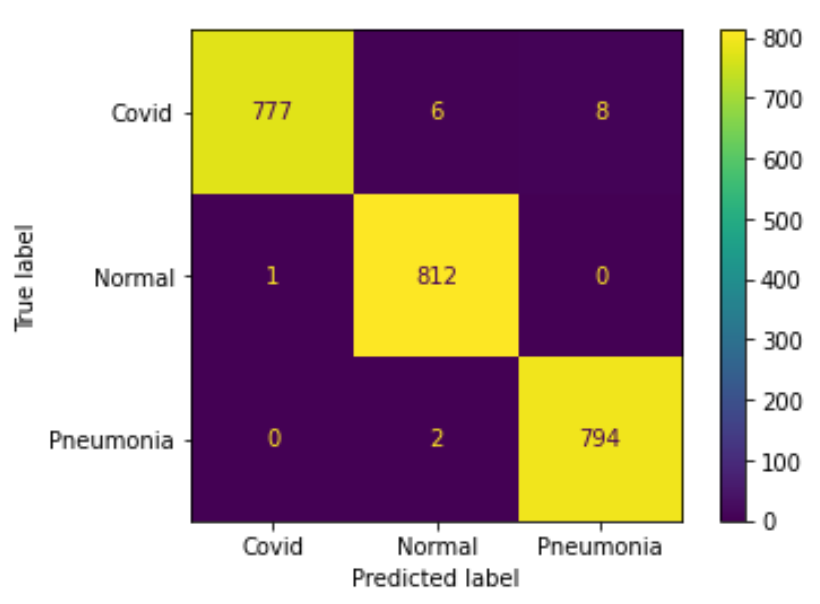
實驗五
人數平衡 + 無 data augmentation
Train on 3840 samples, validate on 960 samples, test on 1200 samples
- Label covid 取 500 人 ( 1 人 4 張 )
- Label normal 取 500 人 ( 1 人 4 張 )
- Label Pneumonia 取 500 人 ( 1 人 4 張 )
訓練過程與測試結果:
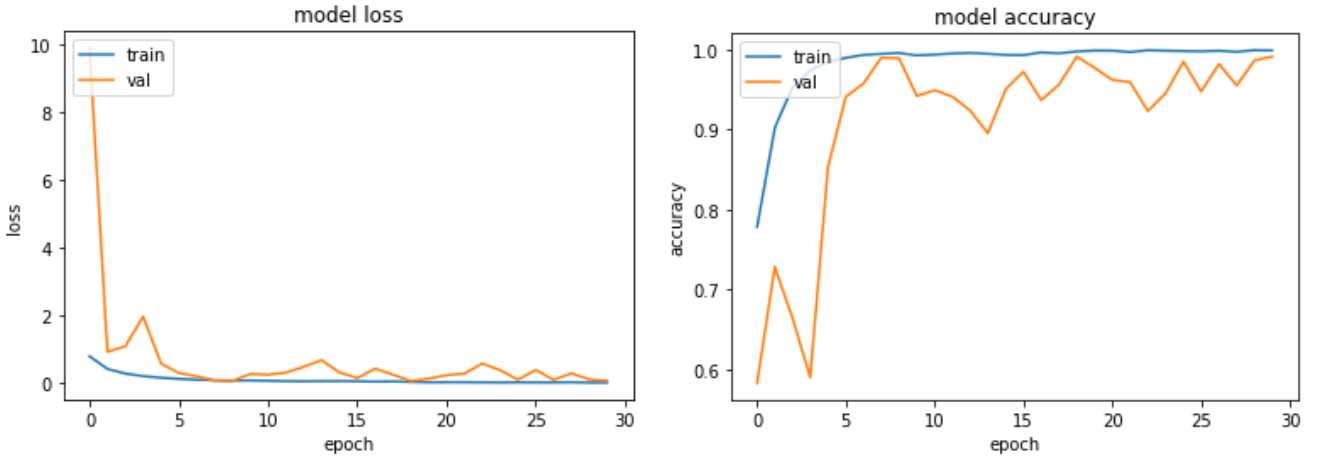
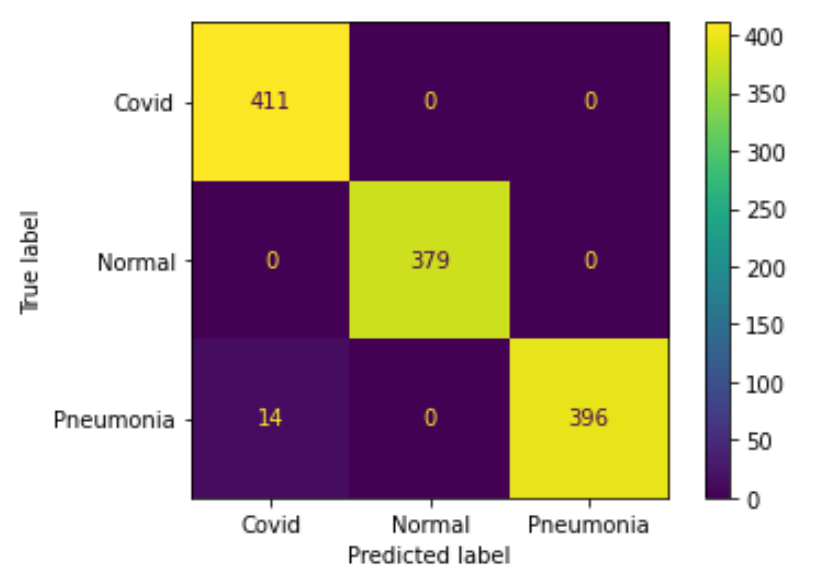
實驗六
人數平衡 + 有 data augmentation (數量 1:1 加入隨機旋轉圖片)
Train on 7680 samples, validate on 1920 samples, test on 2400 samples
- Label covid 取 500 人 ( 1 人 4 張 )
- Label normal 取 500 人 ( 1 人 4 張 )
- Label Pneumonia 取 500 人 ( 1 人 4 張 )
訓練過程與測試結果:
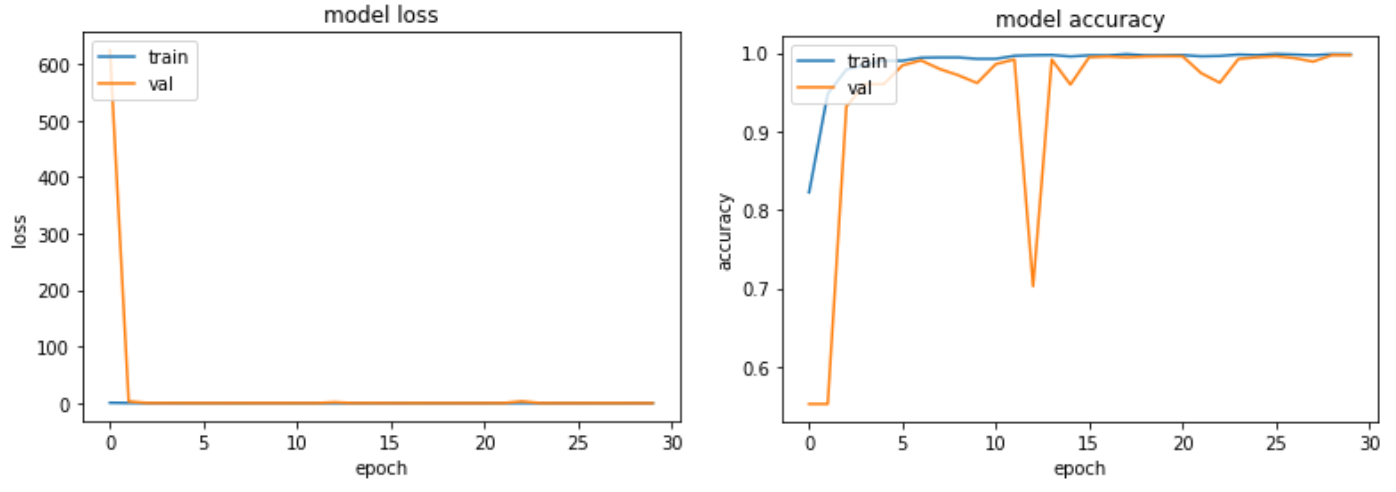
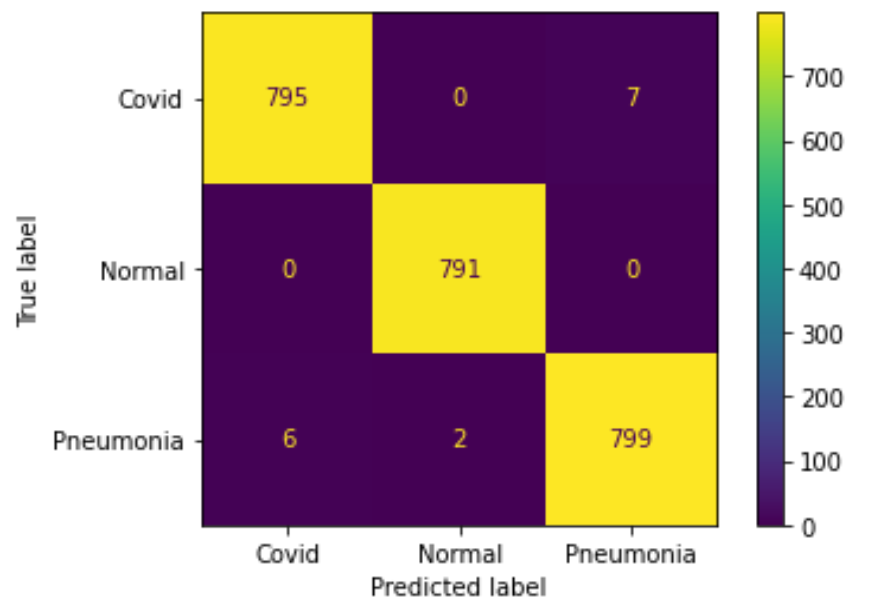
結論
在實驗(一)與實驗(二)中,不論是否有做 data augmentation,其結果都差不多,僅有一、兩張 CT 照預測錯誤,測試準確率高達 99.7%。 雖然乍看之下準確率非常高,然而深究其因可以發現,我們是續向抓取每個 label 前 2000 張照片,所以病人總數不多,但每個病人的 CT 照重複數極高。 我們接著將 6000 張照片取完後再用 Scikit-Learn 的 train_test_split() 來隨機分成 8:2 的訓練、測試資料集,所以測試資料集的內容會與訓練資料有極高的重複性 (同個病人的不同 CT 照),最終造成準確率異常高的現象。
在實驗(三)中,因為原先 dataset 裡的 Covid 病人數量有 2000,佔了整體約 63%, 所以模型在訓練時傾向預測成 Covid。 在之後的測試結果中可以看出,模型將 60 個 Pneumonia 患者錯誤預測成 Covid 患者,可見當 CT 照難以判斷出具體病徵時,便傾向猜測為 Covid 病人,準確率約 93.5%。 如果在實驗中加入 augmentation,如實驗(四),雖然病人比例不變,結果卻出現一定程度的改善,整體準確率約落在 99.2%。
為了改善取樣不均的問題,我們設計了實驗(五)與實驗(六),期望能夠更客觀的預測並分類出三種照片。 如果不加 augmentation,準確率是 98.8%;如果加上 augmentation,最終準確率是 99.3%。 符合我們的預期結果。
改善方向
- 因為此資料集包含專家標記與機器標記,所以可以在前處理時就移除可能有問題的影像,或是僅訓練專家標記的影像,進而提升精準度。
- 本次實驗為了增加訓練速度,僅取 6000 張圖像,若硬體資源充足可以考慮將 19 萬張影像全部內入考量,增加判斷的客觀性。
- 這次資料集所附帶的 csv 檔,除了疾病標記外,也包含部分病人的年齡、性別、國家,可以納入討論做進一步的調查與分析。
- 訓練另外兩個 Covid-Net 資料集 (X光、超音波),與之交互比對來提高判斷準確率。
Next: Face Mask Detection Using YOLO Model
Footnotes
Wiki 嚴重特殊傳染性肺炎 (https://zh.wikipedia.org/zh-tw/2019冠状病毒病) ↩
COVID-Net (https://alexswong.github.io/COVID-Net/) ↩
C. Szegedy, S. Ioffe, V. Vanhoucke, A. Alemi, "Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning," Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31, no. 1, Feb. 2017, doi: https://doi.org/10.1609/aaai.v31i1.11231. ↩
Y. Ding, Z. Li, D. Yastremsky, "Real-time Face Mask Detection in Video Data", arXiv preprint arXiv:2105.01816, 2021 ↩
COVIDx CT-2 Dataset, Kaggle, 2020 (https://www.kaggle.com/hgunraj/covidxct/) ↩