- Published on
Face Mask Detection Using YOLO Model
- Authors

- Name
- Ryan Chung

簡介
近年來,COVID-19 的肆虐對全球造成了重大的影響。 美國疾病控制和預防中心(Centers for Disease Control and Prevention, CDC)指出,COVID-19 主要通過人們呼吸、說話、咳嗽或打噴嚏時產生的飛沫進行傳播。 戴口罩是目前最主流的做法,能夠阻擋 80% 呼吸道感染的機率,實行上簡單且有效。 因此,許多口罩檢測和監控系統被開發來監視醫院、機場、大眾運輸等公共空間。 這次專案即是要使用當前最紅的 YOLO 模型來實作口罩偵測的系統。
模型介紹
在傳統的物件偵測中(例如 R-CNN 或其衍伸版 1 ),我們首先會做 region proposal,也就是找出特徵明顯的 bounding box,接著再將各個子圖丟進去 CNN 做特徵擷取和分類,稱作 two-stage 的物件偵測。
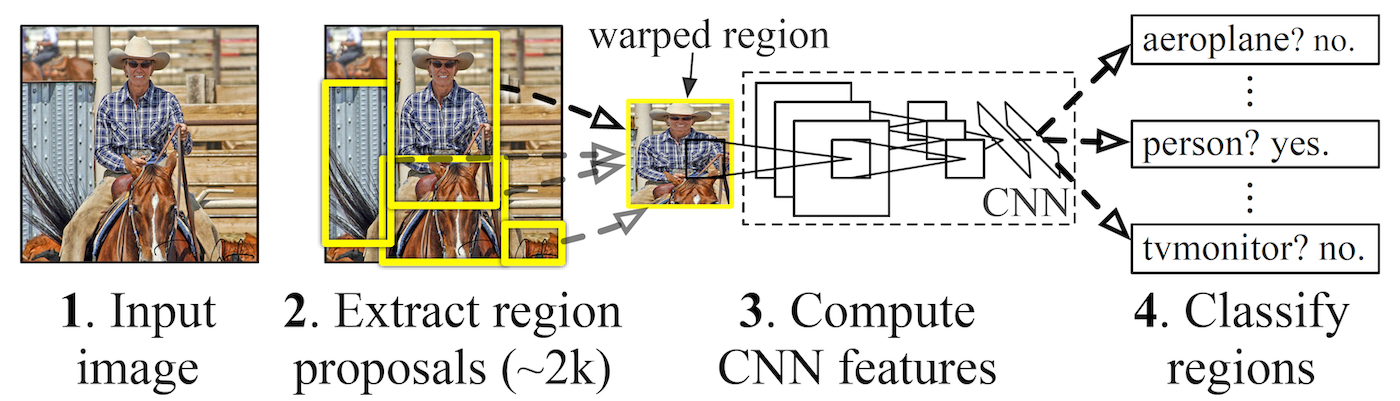
這個作法雖然效果良好,如果面對大量的 regions,每一個都必須丟進去 CNN 做運算,訓練過程複雜且耗時甚巨。 有鑑於此,開始有人提出 one-stage 的的模型,企圖將物件「偵測」與「辨識」一步到位,例如 Single Shot MultiBox Detector (SSD) 2 以及 You Only Look Once (YOLO) 3 。
YOLO 首先將圖片分割成很多網格,然後以每個網格為基準去推算可能的 bounding box 中心、邊界和信心分數 (confidence score),如下圖中的黑色框框。 有了 bounding box 後,還要同時計算每個網格在各個類別中的機率,如下圖中藍色網格代表高機率是狗、黃色代表腳踏車、粉紅色代表汽車。 有了這些參數,就可以框選出所有可能的 bounding box 及其中心所對應的物種類別。
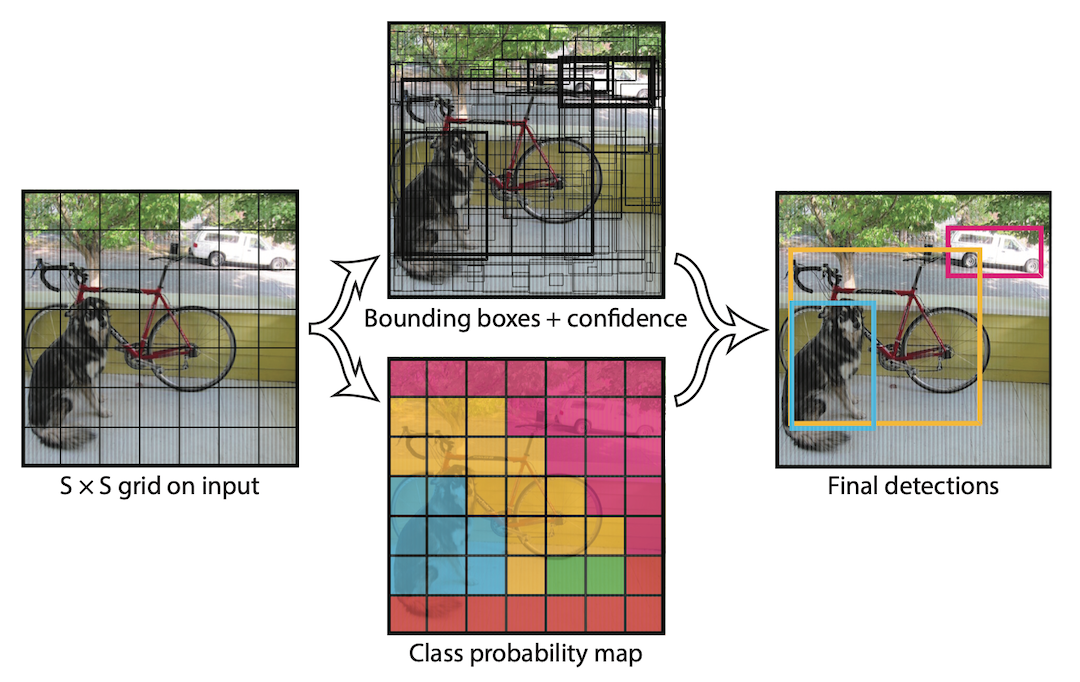
接著我們需要將所有 bounding box 的信心分數以某個閾值 (threshold) 作篩選,移除大量無意義的物件。 然後再透過 Non-Maximum Suppression (NMS),將所有相鄰的 bounding box 合併成唯一。 詳細的計算方式與圖片來源可以參考 這篇文章,在此先不贅述。

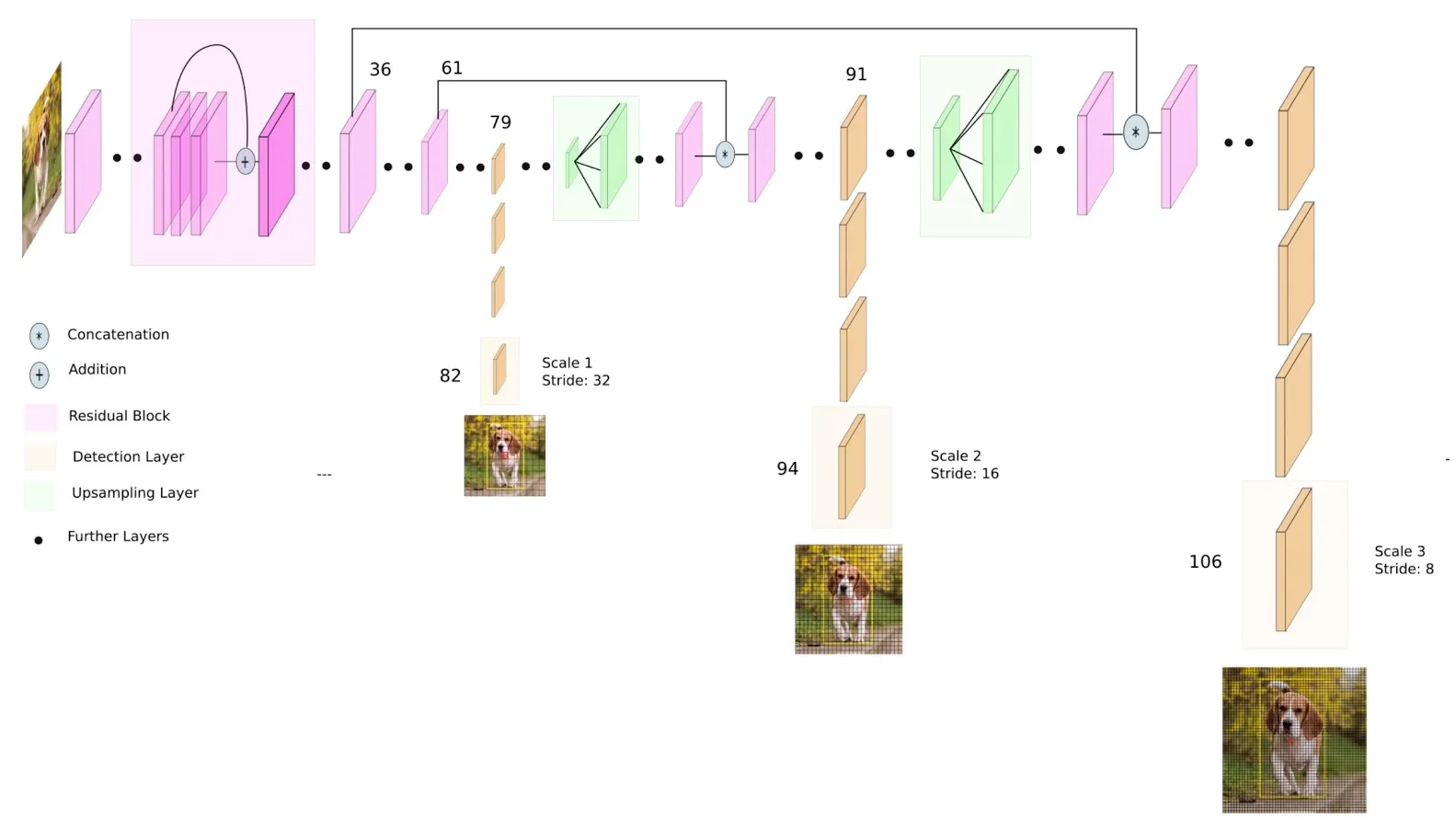
以 YOLO v3 為例,最終模型如下圖所示 4,backbone 採用 DarkNet53,除了 convolution layers 還包含 residual block (為了讓深層網路可以順利學習,可參閱 Part1 內容)。 其中,抽出三層不同尺寸的輸出做物件偵測,可以蒐集到不同特徵,並使用 binary cross-entropy 做 multi-label 的標記,最終得到以下三種 loss:
- lbox, loss from finding bounding box
- lcls, loss from classifing
- lobj, the probability that bounding box contain object
效果如下面影片,可見其辨識物體的能力非常出色。
後來 YOLO 之父 Joseph Redmon 宣布退出電腦視覺領域,但這並不影響 YOLO 的發展。 到了 YOLO v4 ,backbone 改為 CSPDarknet53,物件偵測的模型由 FPN 改為 SPP + PANet,其他細節也做了諸多微調,可以參考 這篇文章。 值得一提的是 YOLO v4 的三位作者中,兩位是來自台灣中央研究院的研究員。
改良後的 YOLO v4 在性能上非常卓越,average precision (AP) 比起 YOLO v3 多了近 10%,可說是目前最快最準的物件偵測演算法。 5
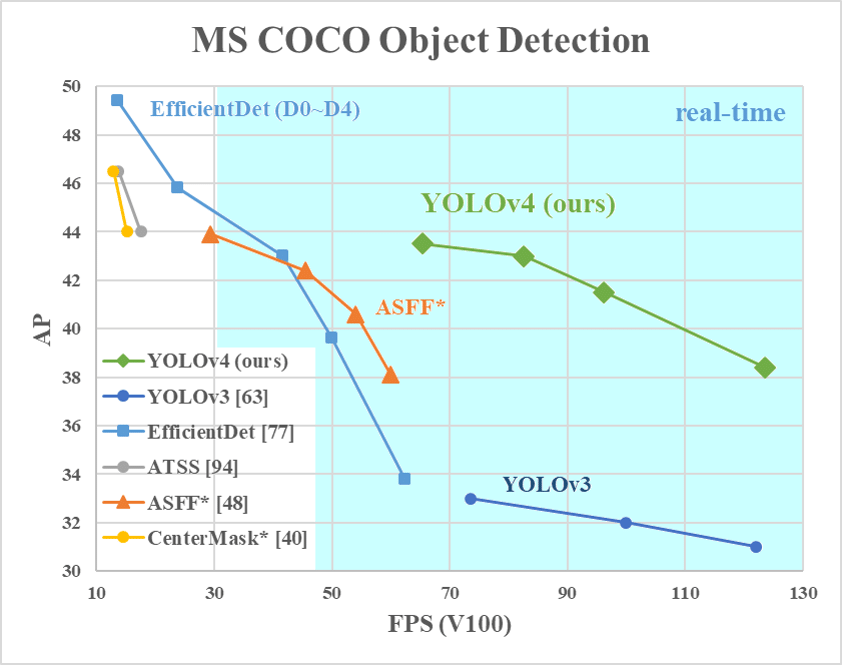
本次專案將同時使用 YOLO v3 與 v4 進行實作。
資料集介紹
我們主要參考這篇論文「WearMask: Fast In-browser Face Mask Detection with Serverless Edge Computing for COVID-19 6」進行資料蒐集與整理,包含以下內容:
- 1,138 additional images from the internet
- total 9,097 images with 17,532 labeled boxes and classes (either Mask or No-Mask)


以上資料都可以在原作者的 Github 上找到。
實驗結果
我們將上述資料 80% 作為 training and validation 20% 作為 testing,套用至 YOLO v3 與 v4 後結果如下表所示:
- YOLOv3: mean average precision (mAP@0.50) = 95.5 %
| Class | Average Precision |
|---|---|
| NoMask | 93.5% |
| Mask | 97.5% |
- YOLOv4: mean average precision (mAP@0.50) = 93.43 %
| Class | Average Precision |
|---|---|
| NoMask | 89.77% |
| Mask | 97.09% |
進一步觀察個案後可以發現,在人臉清晰且鼻子未覆蓋至口罩內的面孔,皆可以正確辨識結果。



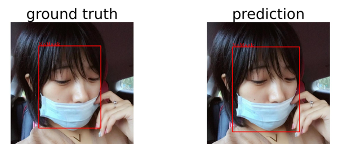
但若人臉過多、過小,或是臉部被遮擋,都有可能導致無法辨認或辨認失敗。也有發現 ground truth 標錯的案例。




改善方向
其實在 MAFA 的資料集中,將人臉畫分為四個區域 (eyes、nose、mouth、chin),以此對遮擋程度做分級 (occlusion degree),並進一步細分為被人體或紋理等四種遮擋方式 (mask type)。
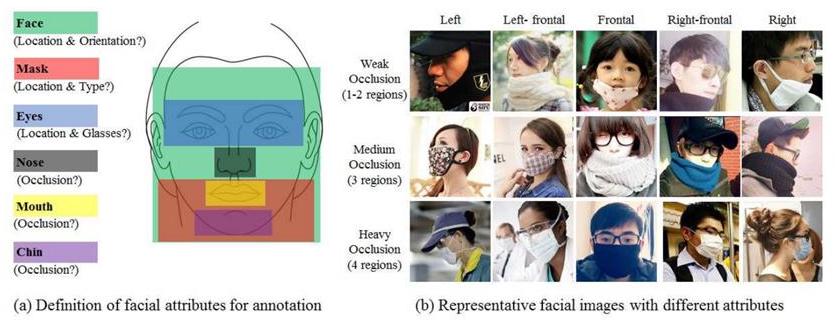
如果能善用這些 annotations,將有助於大幅增加辨識準確度。 實際上在參考論文中 6 ,就將口罩配戴分為三類:正確配戴、不正確配戴、無配戴,並能夠正確辨識這些情境。

隨著相關研究的推進,更準確有效率的模型,搭配上詳盡的資料集與正確的訓練方式,可以將物件偵測這個領域做到淋漓盡致,應用在生活周遭(例如自動駕駛的影像辨識系統)。
Footnotes
John A, Meva D. "A comparative study of various object detection algorithms and performance analysis," International Journal of Computer Sciences and Engineering, Vol.8, no.10, pp.158-163, Oct 2020. ↩
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Fu, A.C. Berg, “SSD: Single Shot Multibox Detector”, Springer, Vol.9905, pp.21-37, 2016. ↩
J. Redmon, Santosh Divvala, R. Girshick, A. Farhadi, "You Only Look Once: Unified, Real-Time Object Detection," In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 779-788, 2016. ↩
Larkspurvc, "Object Detection Using YOLOv3," Medium, 2021, https://medium.com/@larkspurvc718/object-detection-using-yolov3-f7c75515ddc ↩
A. Bochkovskiy, CY. Wang, HY. Liao, "YOLOv4: Optimal Speed and Accuracy of Object Detection." arXiv preprint, arXiv:2004.10934, 2020. ↩
Wang Z, Wang P, Louis PC, Wheless LE, Huo Y, "WearMask: Fast in-browser face mask detection with serverless edge computing for COVID-19," arXiv preprint, arXiv:2101.00784, Jan 2021. ↩ ↩2
S. Yang, P. Luo, C.-C. Loy, X. Tang, "Wider face: A face detection benchmark," in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5525-5533, 2016. ↩
Ge S., Li J., Ye Q., Luo Z., "Detecting masked faces in the wild with LLE-CNNs," in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2682-2690, 2017. ↩