- Published on
Deep Learning Basic - to See
- Authors

- Name
- Ryan Chung

目錄
本篇是深度學習基礎系列文第二章,著重在電腦視覺,包含卷積神經網路的原理、各種延伸架構及其應用。 其他內容請參考以下連結:
- DL 首部曲: to Know (神經網路)
- DL 二部曲: to See (電腦視覺)
- DL 三部曲: to Speak (自然語言) (待更新)
- DL 四部曲: to Think (大型模型) (待更新)
緒論
還記得我們在上一章曾經提過,人工智慧的發展分為以邏輯推理為主的「符號主義 (Symbolicism)」,以及用神經網路歸納經驗的「聯結主義 (Connectionism)」。 前者曾經繁榮幾十年,卻始終無法有效解決感知問題(例如辨識物體); 而後者之所以近年來蓬勃發展,可以歸功於一個關鍵轉捩點,那就是 卷積神經網路 (convolutional neural network, CNN) 在影像辨識上的成功。
對於人類來說,「看」是我們最直接理解外在環境的方式。 舉凡辨認親友的臉孔、閱讀文章、觀察路況、觀察自然實驗等,都是建立在「看」這個行為上。 然而對於電腦來說,即時辨認影像是非常困難的問題。 假設我們將視野模擬成 16K 全景影像 (約 132 MP),對於 RGB 三原色 (24 bits) 就有 132 x 106 pixels x 24 bits ≈ 3.96 Gbits ≈ 495 MB。 假設以平均 60 FPS 的幀率處理視覺,495 MB x 60 ≈ 29.7 GB/sec,這是一個非常驚人的頻寬。
實際上,我們視神經的資訊傳遞速率只有大約 106 bit/sec,思考速率只有約 10 bits/sec,遠低於上面的數值 2 3。 這是因為我們的大腦做了極大量的資訊壓縮,只關注必要的部分。 換句話說,我們雖然「看見了」整個世界,但是只「處理」非常少的細節。 但對於電腦來說,如何從大量的像素中萃取出真正必要的資訊,一直是電腦視覺 (computer vision) 數十年來挑戰的目標。
早期的電腦視覺非常依賴 特徵工程 (feature extraction),使用邊緣檢測、角點檢測、SIFT 4、HOG 5 等方法來偵測並萃取影像中的局部性特徵,再搭配 SVM 等機器學習方法來進行分類。 特徵工程非常仰賴專家的知識與技術,雖然在某些場域表現不凡,但通常需要針對該場域做精細的調整。 這正是為什麼 Yann LeCun 成功使用卷積神經網路來辨識手寫數字 (MNIST) 是這麼重要,因為這是人類首次使用神經網路來自動學習影像特徵,大幅減少人為介入的程度。 然而受限於硬體效能與 overfitting 等問題,在更複雜的圖案與任務上並沒有很好的表現,以至於在當時並沒有蓬勃發展。 一直到 2012 年 AlexNet 在 ImageNet 競賽上一戰成名,才讓 CNN 真正受到重視。
2019 年 Rich Sutton 在他的部落格發表一篇看似平淡無奇卻寓意深遠的文章「The Bitter Lesson」。 他認為在人工智慧的發展歷史中,最重要的教訓就是:使用更多的計算資源來學習更通用的知識,通常會比使用專家知識來解決特定問題更有效。 也許我們在研究初期透過領域知識建立規則和假設,可以獲得初步的成果,最終的成功卻往往令人難以接受,因為它不是建立在以 人類知識 為中心的方法上,而是建立在更基礎且通用的元方法 (meta-method),且隨著計算資源的增長會變得更加強大。 西洋棋 Deep Blue 是如此、圍棋 AlphaGo 是如此、卷積神經網路更是如此。 時至今日已經沒有人在手刻特徵,而是直接使用神經網路來自動搜索特徵。而這正是深度學習萌芽的起點。
卷積神經網路
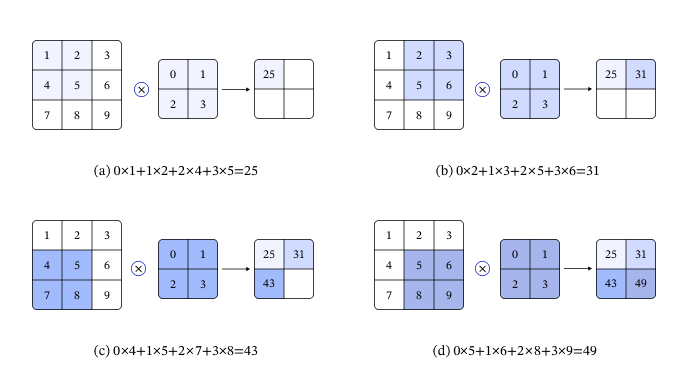
那究竟什麼是卷積神經網路 (CNN) 呢?其實就是將 卷積 (convolution) 與 池化 (pooling) 等數學運算,應用在神經網路的架構上。 所謂的卷積,就是將一個小濾鏡 (filter, or convolution kernel) 在影像上滑動,計算每個位置的加權和,這樣可以萃取出影像中的局部特徵。 以下圖為例,對於一個 3x3 的影像,使用 2x2 的濾鏡 [[0, 1], [2, 3]] 進行卷積運算,假設步長 (stride) 為 1,計算後得到一個 2x2 的全新特徵圖 (feature map) [[25, 31], [43, 49]]。 這麼做就相當於透過濾鏡權重來簡化原始圖像,不直接使用密集層 (dense layer) 來處理每個像素,避免過度稀疏的資訊造成模型訓練失敗。
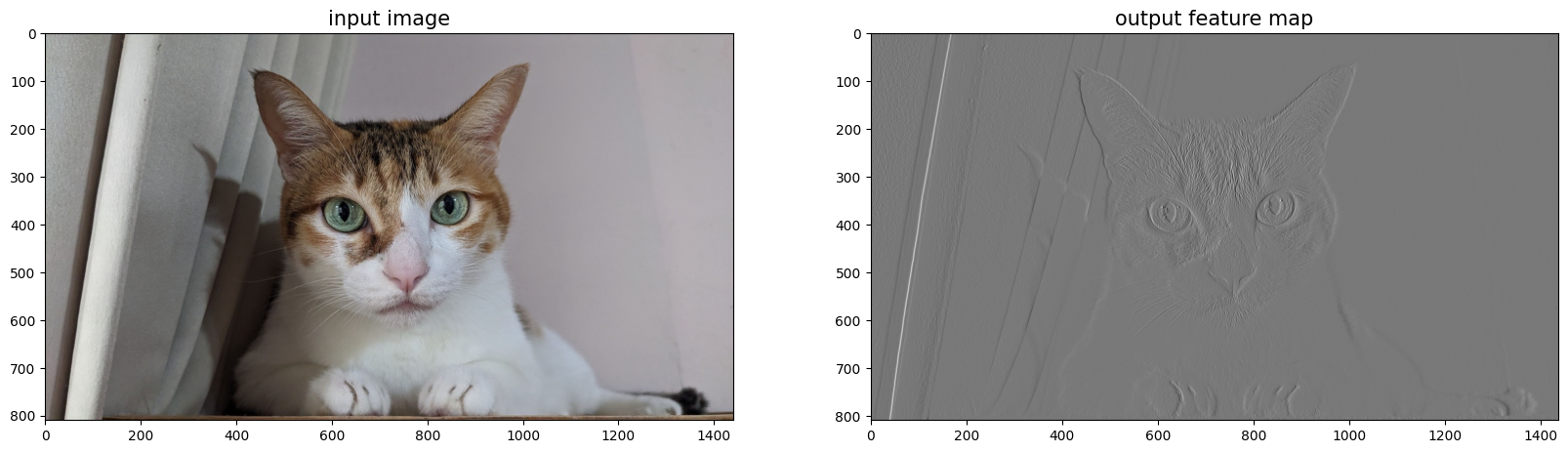
以實際案例來說,我們可以設計一個 10x10 的濾鏡,其中每個值均為 1。 這樣加權後就會把周圍的像素取平均,使得影像變得更平滑、噪訊更低,同時也更模糊(程式碼與圖片請參考 Github)。
import tensorflow as tf
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
# Read the image and convert to grayscale
img = Image.open('/content/cat.jpg').convert('L')
img = np.array(img)
# Create initialization parameters (average filter)
w = np.ones((10, 10, 1, 1), dtype='float32')
# Define the convolution layer
conv = tf.keras.layers.Conv2D(
filters=1,
kernel_size=(10, 10),
strides=(1, 1),
padding='valid',
use_bias=False
)
...

另一個常見的案例是邊緣偵測,我們可以透過一個 3x3 Sobel X 濾鏡 [[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]],來尋找影像中劇烈的橫向明暗變化。 在這個案例中我們一次處理 RGB 三個通道 (channel),並且將濾鏡複製到每個通道上。
img = Image.open('/content/cat.jpg')
# Set kernel parameters (Sobel X)
w = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], dtype='float32')
w = w.reshape((3, 3, 1, 1))
# Since input channels = 3, replicate kernel across 3 input channels
w = np.repeat(w, 3, axis=2) # shape becomes (3, 3, 3, 1)
conv = tf.keras.layers.Conv2D(
filters=1,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
use_bias=False
)
...
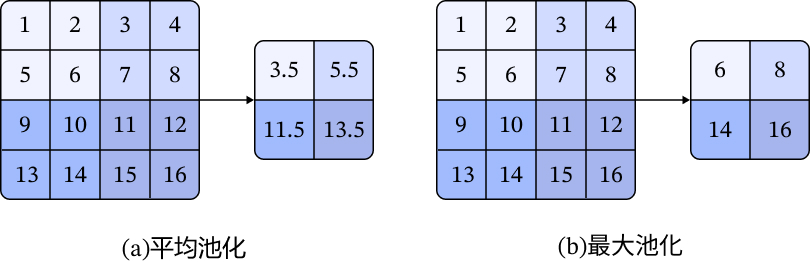
使用卷積來掃描圖片,會將原始圖片轉變為一個尺寸稍小的特徵圖 。 如果想要讓特徵圖與原始尺寸一致,我們會在圖片四周加上 padding(通常是用 0),這樣可以避免特徵圖尺寸過小。 最後我們還可以加上池化層,常見平均池化 (average pooling) 與最大池化 (max pooling),也就是對窗口內的元素取最平均值或最大值,類似於將影像平滑化或加強對比,特別是後者常用於進一步提取特徵與縮小特徵圖的尺寸。
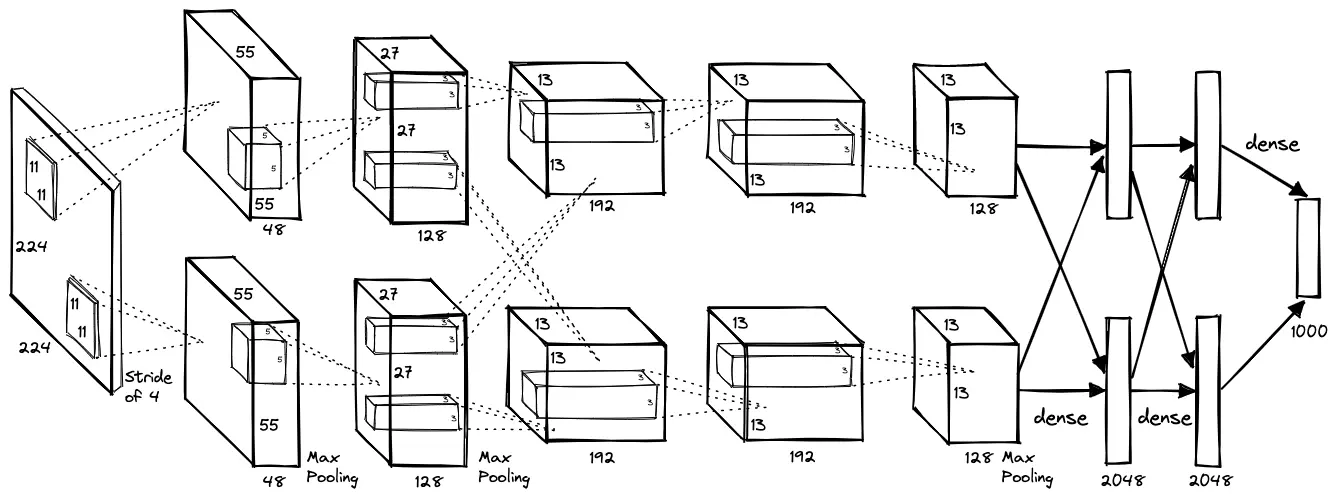
有了上述知識,我們終於可以看懂 AlexNet 的架構。 其實就是將 224x224x3 的原始影像拆成上下兩半(受限於當時硬體能力不足),以 11x11、5x5、3x3 等不同大小的濾鏡作卷積和最大池化運算, 接著展平 (flatten) 後送入密集層 (dense layer),最終輸出一個 1000 維的向量,表示對應到 ImageNet 資料集的 1000 個類別的機率分布。
圖像分類
接下來我們將實際利用 CNN 來解決圖像分類的問題。 除了前一章提到的 MNIST 手寫數字以及大規模圖像資料集 ImageNet,其實還有一個更適合教學的小規模資料集 CIFAR (Canadian Institute for Advanced Research)。 CIFAR 分為 CIFAR-10 與 CIFAR-100,皆為六萬張 32x32 的小圖片,差別只在分成 10 類或 100 類。 我們一樣可以直接使用 keras.datasets 來下載 CIFAR-10,並將其分割為訓練資料與測試資料。 接著將影像標準化至 0 附近以方便模型訓練跟收斂,然後將標籤做 one-hot encoding。
# load dataset
cifar_dataset = keras.datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar_dataset.load_data()
# data standardization
mean = np.mean(train_images)
stddev = np.std(train_images)
train_images = (train_images - mean) / stddev
test_images = (test_images - mean) / stddev
# one-hot encoding
train_labels = to_categorical(train_labels, num_classes=10)
test_labels = to_categorical(test_labels, num_classes=10)
接著我們一樣使用 Sequential() 來定義序向的模型結構。 在這邊我們直接使用四層卷積神經網路,只需要將剛剛介紹的卷積層 (Conv2D) 與最大池化層 (MaxPooling2D) 疊加起來, 再配合丟棄法 (Dropout) 等解決 overfitting 的手段,持續觀察並調整模型參數,就可以成功訓練濾鏡的權重。
# model architecture
model = Sequential()
model.add(Conv2D(64, (4, 4), activation='relu', padding='same', input_shape=(32, 32, 3)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (2, 2), activation='relu', padding='same', strides=(2,2)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=2))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
# model compilation and training
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics =['accuracy'])
model.summary()
history = model.fit(
train_images, train_labels,
validation_data = (test_images, test_labels),
epochs=EPOCHS, batch_size=BATCH_SIZE, verbose=2, shuffle=True
)
以第一層 Conv2D 來說,單層濾鏡的尺寸是 4x4x3 (RGB channel) = 48,再加上 bias 會是 49 個參數。 而這一層有 64 個濾鏡,總共會有 49x64=3136 個參數要訓練。 第二層 Conv2D 的濾鏡參數量是 2x2x64 (前一層輸出的 channel) + 1 (bias) = 257,總共 257x64=16448 個參數。 可以執行 model.summary() 來確認這一點。 如果是使用 Google Colab 的 T4 GPU 來執行,莫約過個幾分鐘就可以訓練完成了。 預測結果如下呈現,可見整體表現不錯,但依舊存在少量錯誤辨識錯誤。

如果想要有效解決像 ImageNet 這種等級的問題,就需要更大更複雜的神經網路,例如 VGGNet 8(16 層)、GoogLeNet 9(22 層)、ResNet 10(152 層)等。 ResNet 比起前幾個神經網路,比較特別的是引入了 殘差模組 (residual module) 的概念,透過跳接的方式將輸入直接拉到後面幾層的輸出,避免過深的網路導致梯度消失。 後續幾個著名模型也都採用這個概念,例如 Google InceptionResNet 11。
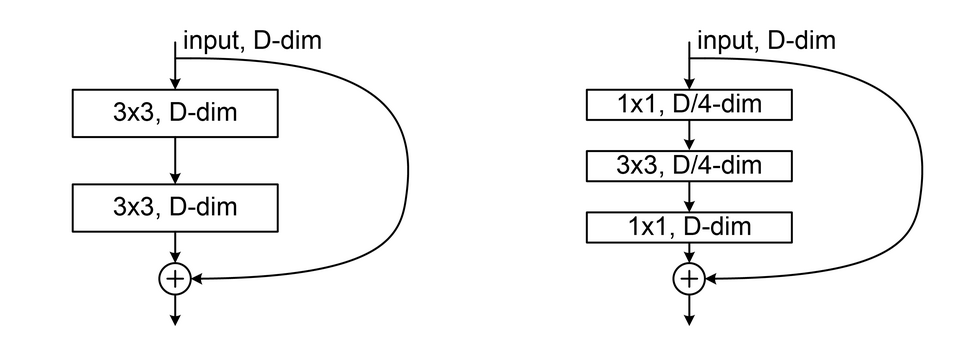
如果要使用這些複雜的模型,手動從頭建立不免有些費工。 我們可以直接從 keras.applications 中下載該模型的結構和權重。 只要將輸入圖片轉成合適的規格,就可以直接使用訓練完的模型進行預測。
from tensorflow.keras.applications import resnet50
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.applications.resnet50 import decode_predictions
# load and resize the image to 224x224 pixels (required by ResNet50)
image = load_img('/content/cat.jpg', target_size=(224, 224))
image_np = img_to_array(image)
# add an extra dimension to match the model's input shape (batch size, height, width, channels)
image_np = np.expand_dims(image_np, axis=0)
# load the pre-trained model
model = resnet50.ResNet50(weights='imagenet')
# data standardization
X = resnet50.preprocess_input(image_np.copy())
# prediction
y = model.predict(X)
predicted_labels = decode_predictions(y)
print('predictions = ', predicted_labels)
我們將前文的貓咪圖片喂給模型,執行預測後可以看到機率前五高的類別, 分別是埃及貓 (egyptian cat)、虎斑家貓 (tabby)、虎斑貓 (tiger cat)、猞猁 (lynx)、浴簾 (shower curtain)。 有趣的是,模型不只可以看出貓咪,也大致辨識出了貓咪旁邊的窗簾。
predictions = [[
('n02124075', 'Egyptian_cat', 0.63451874),
('n02123045', 'tabby', 0.20975216),
('n02123159', 'tiger_cat', 0.047797903),
('n02127052', 'lynx', 0.036935005),
('n04209239', 'shower_curtain', 0.023538478)
]]
除了直接使用預訓練的模型來預測圖片,我們還可以藉由遷移式學習進一步將模型 微調 (fine-tune) 成適合我們的需求。 例如我們想將 ImageNet 預測的 1000 種類別更換成我們自定義的 100 種物體,可以將模型最後面的密集層移除,改成我們自己的分類器。 接著,我們將模型的卷積基底 (convolution base) 凍結,在訓練時只更新分類器的權重。 這麼做可以保留預訓練時模型本身學到的特徵,但又可以將這種辨識能力應用在新的場景中。 而且因為只需要訓練後面的密集層,所以訓練過程會比全參數的訓練要更快且更容易收斂。
from tensorflow.keras.layers import GlobalAveragePooling2D
conv_base = resnet50.ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
conv_base.trainable = False # freeze convolution base
model = Sequential()
model.add(conv_base)
model.add(GlobalAveragePooling2D())
model.add(Dense(256, activation='relu'))
model.add(Dense(100, activation='softmax'))
當我們訓練完分類器後,如果想追求更進一步的效果,可以解凍部分卷積基底並搭配非常低的學習率,來繼續訓練並微調該模型的權重。 這個技巧對於未來想在有限的硬體上訓練超大模型非常有幫助。
for layer in conv_base.layers:
layer.trainable = True
...
物件偵測
在前面的例子中,我們可以發現影像辨識模型不只可以辨識出貓咪,也可以辨識出旁邊的窗簾。 這必須歸功於 CNN 成功的特徵萃取,讓密集層順利將部分特徵訊號送到對應的分類中。 然而若我們想知道貓咪與窗簾之間的關係,也就是物體實際的 位置,就無法單靠 CNN 來完成。
一種可能的方法是將原始圖片拆分成許多子圖,再拿這些子圖去預測裡面到底有什麼東西。 理論上只要子圖拆分得夠多夠準,就有可能框選出正確的物體。 我們可以將預測為該物體的數個子圖錨框 (anchor box) 與真實的檢測框 (bounding box) 做 交併比 (Intersection over Union, IoU) 計算, 也就是將兩者的交集面積除以聯集面積,就可以得出每個錨框的 IoU 分數,以此為依據去選定物體的最佳位置。

我們不難發現,關鍵問題是如何找出好的 anchor box,才不會陷入窮舉的地獄。 這個找出 anchor box 的動作又稱作 region proposal,以此為基礎發展出第一個經典物件偵測模型 R-CNN 12。 R-CNN 會使用 selective search 先依據影像的顏色與紋理相似度,計算出約 2000 個 anchor box, 再利用 AlexNet 當作 backbone 做特徵擷取和分類,稱作 two-stage 的物件偵測。
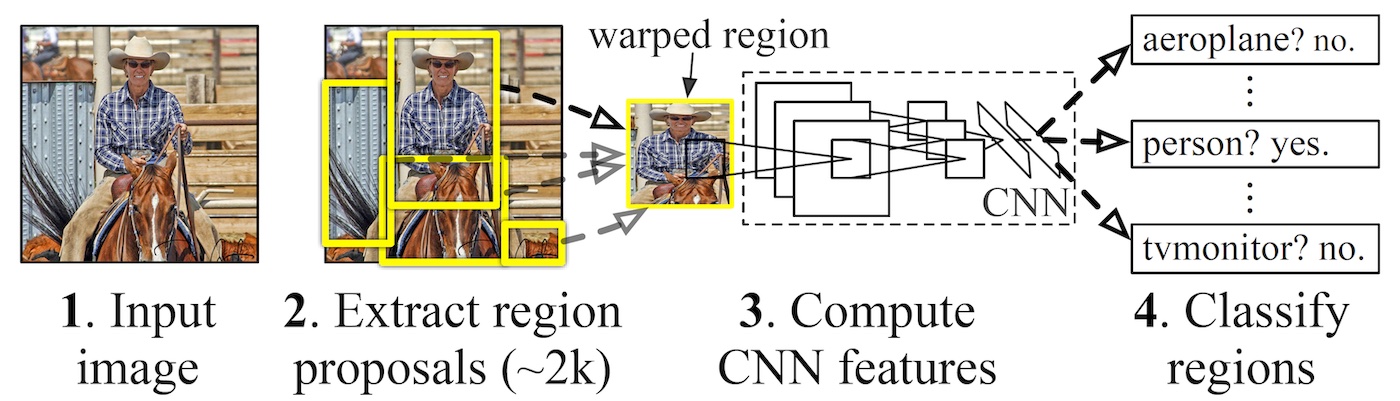
這個作法雖然效果良好,如果面對大量的 regions,每一個都必須丟進去 CNN 做運算,訓練過程複雜且耗時甚巨。 有鑑於此,開始有人提出 one-stage 的的模型,企圖將物件「偵測」與「辨識」一步到位,例如 Single Shot MultiBox Detector (SSD) 13 以及 You Only Look Once (YOLO) 14 。
YOLO 首先將圖片分割成 SxS 個網格,再以每個網格為基準去預測是否含有物體、物體的類別、可能的 bounding box 範圍。 以下圖為例,將原始圖片分成 7x7 個網格,且假設某個網格內含有目標檢測物的 bounding box 中心點,網格左上角的座標是 ,中心點偏移量是 ,則可以列出以下公式:
其中, 是 sigmoid function,其輸出範圍介在 [0, 1] 之間,這樣可以確保 bounding box 中心點必然在該網格內。 例如狗的中心點可能在 ,偏移量 ,中心點就會落在 的位置,乘上網格大小就可以得出圖片精確座標。 另外一個要預測的是 bounding box 的寬高,一樣可以用網格的寬高為基準去列出公式:
其中, 分別是網格的寬高。 我們還需要進一步預測網格內含有物體的信心分數 (confidence score),定義為物體存在的機率乘上 bounding box 與 ground truth 的 IoU。 可以理解為若網格內不存在物體,信心分數的正解就會是 0,反之正解就會是該物體的 IoU,物體類別則可以用 one-hot encoding 來表示其機率。 有了以上資訊,就可以計算總損失值 。
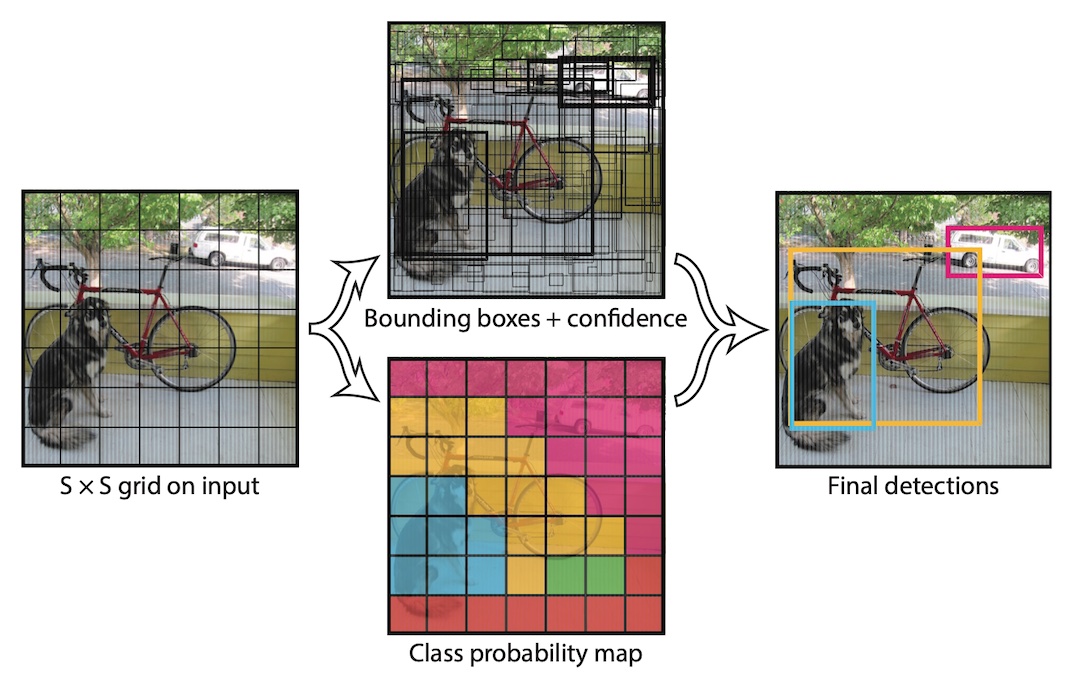
最終模型輸出的維度 (tensor) 將會是 SxS x (Bx5 + C),其中 B 是每個網格要預測的 bounding box 數量, 5 是 ,C 是物體的類別數量。 如果 B = 2,上圖就會有 7x7x2 = 98 個可能的 bounding box。 我們還需要將所有 bounding box 的信心分數以某個閾值 (threshold) 作篩選,先移除大量無意義的檢測框, 再透過 Non-Maximum Suppression (NMS),將所有相鄰的檢測框合併成唯一。 具體方式是先依據信心分數來排序檢測框,再彼此作 IoU 計算,移除過度相似的框 (eg. IoU > 0.5),剩下就會是信心分數最高的獨立檢測框。

效果如以下影片 (2018),可見其辨識物體的能力非常出色。
後來 YOLO 之父 Joseph Redmon 宣布退出電腦視覺領域,但這並不影響 YOLO 的發展。 到了 YOLO v4 (2020),進一步修改 backbone 與物件偵測模型,提高速度與與精準度。 值得一提的是 YOLO v4 的三位作者中,兩位是來自台灣中央研究院的研究員。 YOLO v5 以後,改由民間公司 Ultralytics 持續開發跟維護, 到了 YOLO v8 (2023) 甚至增加 segmentation 功能,能夠把物體的輪廓精確的框選出來。
我們可以直接用 pip 下載 ultralytics,就可以快速測試 YOLO 模型的能力。
pip install ultralytics opencv-python
from ultralytics import YOLO
import cv2
# load the pre-trained model
model = YOLO('yolov8n.pt')
# load the image
image_path = 'cat.jpg'
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# prediction
results = model.predict(source=image_rgb)
result_image = results[0].plot()
該模型在 7.2ms 內就完成推論 (confidence score = 0.89),可見其對於常見物體非常快速準確,適合用在邊緣部署跟即時偵測(例如人臉、車流辨識)。

圖像分割
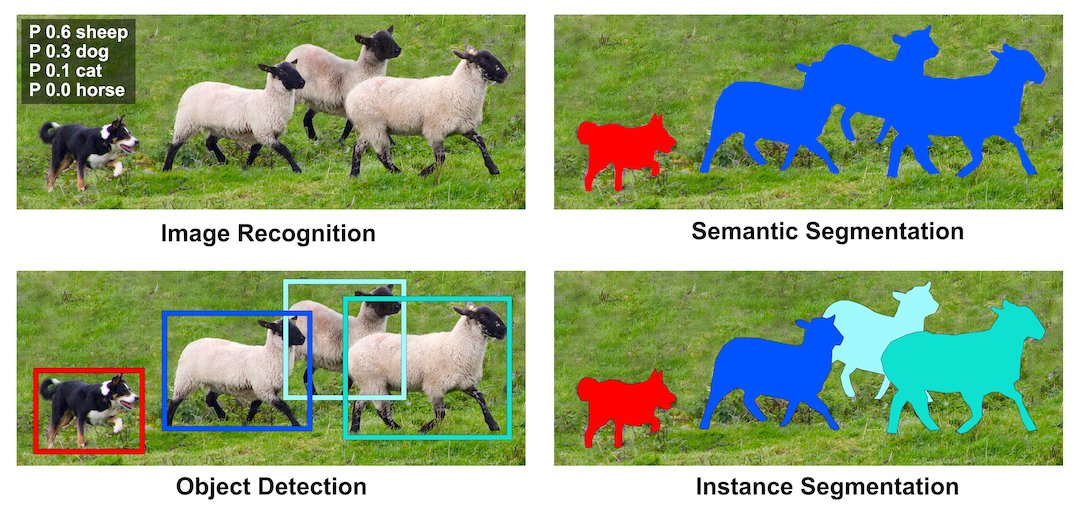
在上面的範例中,我們已經可以大致框選出物體的位置,然而對於更專業的應用(例如醫療影像、工業瑕疵檢測、物體去背等),只有 bounding box 顯然是不夠的。 我們希望有一個模型可以更加精確、甚至是像素級別的辨識出特定物體。 PASCAL (Pattern Analysis, Statistical Modelling and Computational Learning) 是一個由歐盟贊助的學術研究計畫, 於 2005-2012 年間持續舉行電腦視覺相關的競賽 VOC (Visual Object Classes Challenge) 15,也是 ImageNet (ILSVRC) 的前身。 相較於 ImageNet,PASCAL VOC 雖然資料量較少,但包含物件分類、偵測與分割等任務。 這種基於物體類別的遮罩 (mask) 標注,又稱作 語意分割 (Semantic Segmentation)。
然而對於照片內相同類別的物體(例如多隻貓),語意分割無法區分特定個體。 有鑑於此,2014 年 Microsoft 推出了 COCO (Common Objects in Context) 資料集 16,針對不同物體有更精確的標記, 這種分割方式又稱作 實例分割 (Instance Segmentation)。
為了解決圖像分割問題,FCN (Fully Convolutional Networks) 18 將作為分類用的 dense layer 替換成 convolution layer, 把原本透過卷積運算提取的特徵圖,利用 反卷積 (deconvolution) 還原回原圖的大小。 要理解什麼是反卷積,我們必須先知道什麼是上取樣 (upsampling)。 所謂上取樣,就是將一張低解析度圖片變成高解析度的方法,例如我們可以使用插值法 (bilinear) 將兩個像素之間做 padding,就可以變成一張比較大但比較平滑的圖片。 反卷積通常採用 0 作為像素之間的 padding,這樣就可以保留原始特徵,用訓練的方式來學習反卷積核的權重。 這種方式類似於 stride = 1/2 的卷積運算,所以又稱作分數步長卷積 (fractionally strided convolution)。
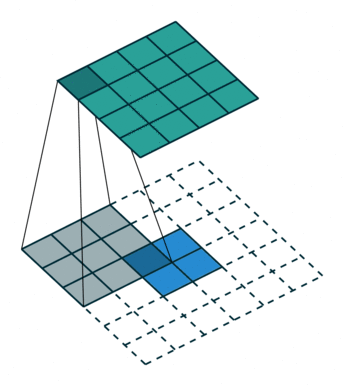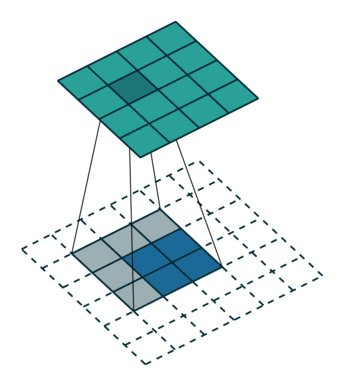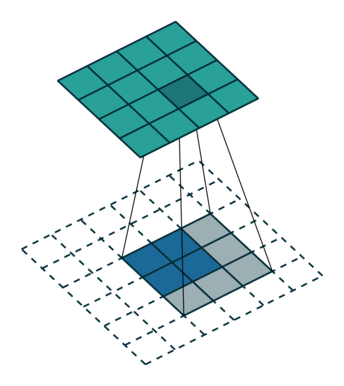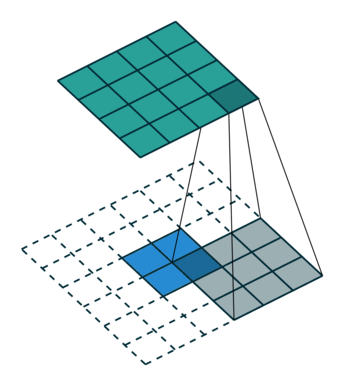
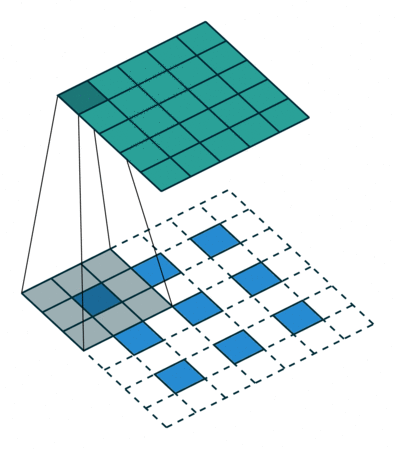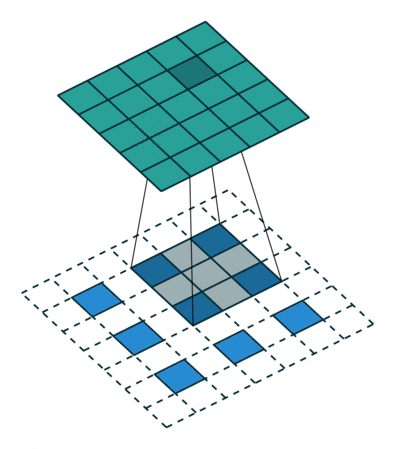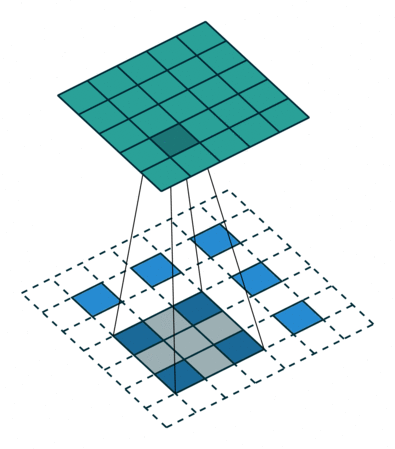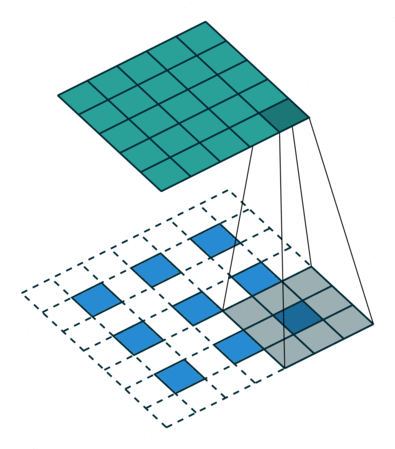
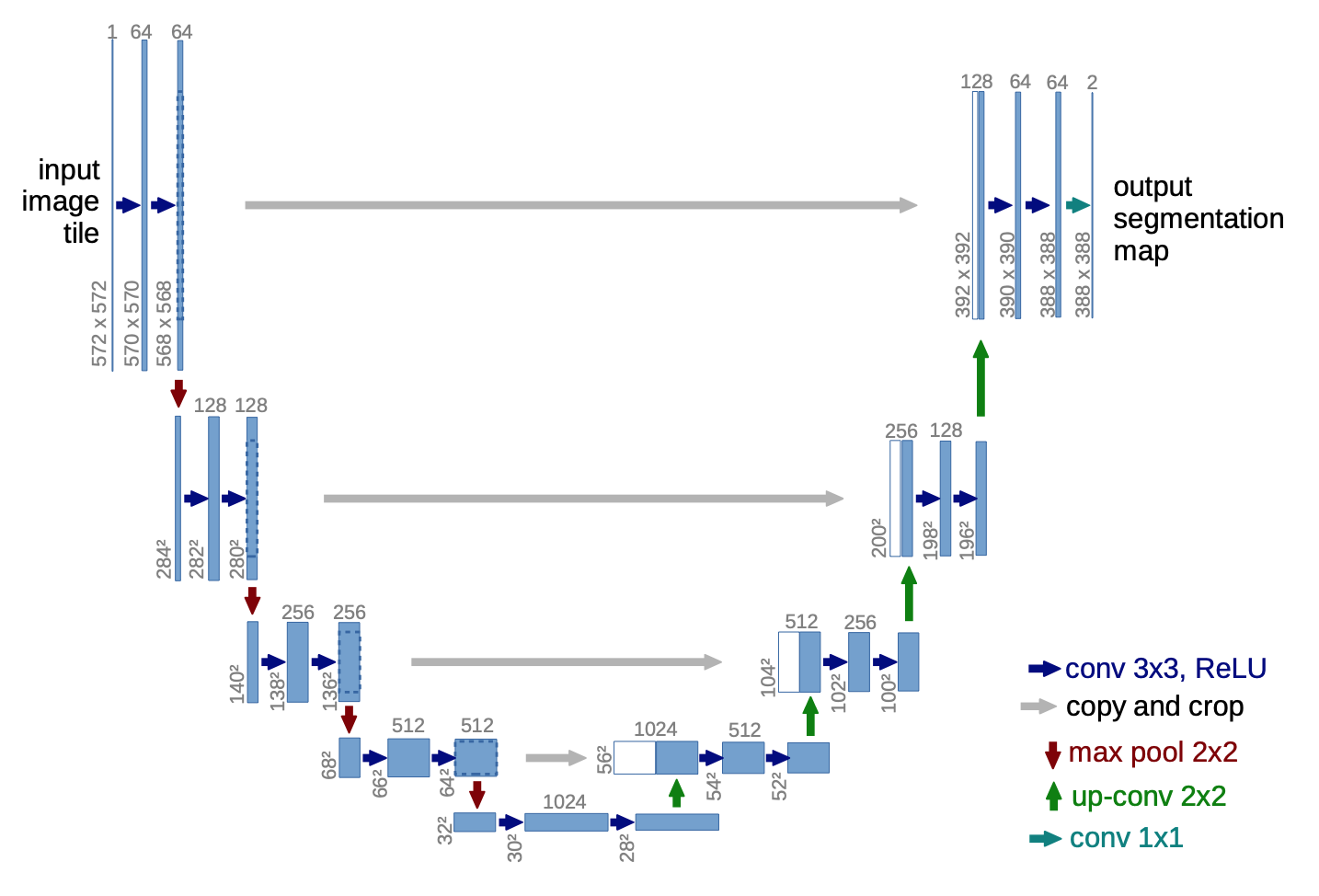
為了避免資訊流失,FCN 還會融合降維前後的特徵圖,但細節表現依舊不佳。 2015 年 U-Net 20 改良了整個架構,把前半卷積與池化等特徵取樣的部分稱作 Encoder,後半卷積與上取樣等特徵還原部分稱作 Decoder, 並在每一層降維前與升維後加上 skip connection,大幅保留原圖的細節。 這對於雜訊、病灶等異常檢測非常重要,特別適合用於醫學影像。 後來有許多基於 U-Net 的衍伸模型,例如修改 backbone 為 ResNet,或是加入 attention 機制等。 2021 年 Nvidia 發表論文 21,認為只要稍微修改一下 U-Net 的 loss 計算方式,就可以有相當好的語意分割效果。
然而,如果我們想標示出特定物體,單靠語意分割是不夠的。 以上面 MS-COCO 的圖片為例,雖然語意分割可以精確辨識每個像素的類別,卻無法精確分割重疊的物體(羊群)。 Facebook AI Research (FAIR) 所推出的 two-stage 模型 Mask R-CNN 22 非常有效解決這個問題。 它使用 ResNet 作為 CNN 骨幹, 串接 Feature Pyramid Network (FPN) 23 來更有效結合各層特徵的細節, 並使用 Region Proposal Network (RPN) 24 來生成 anchor box,最後將這些資訊送給兩個分支,分開預測 class + bbox 以及 FCN mask。 論文中認為這樣可以降低因為訓練 bbox 所造成的 systematic artifact,大幅增加 mask 精準度。
儘管 Mask R-CNN 非常出色,受限其 two-stage 和複雜的網路,運算速度約 10 FPS,尚無法達到工業上 real-time 的即時應用。 還記得先前主打快速預測的 YOLO 嗎?YOLO 之父 Joseph Redmon 在 YOLOv3 文末就曾感嘆:25
Boxes are stupid anyway though, I’m probably a true believer in masks except I can’t get YOLO to learn them.
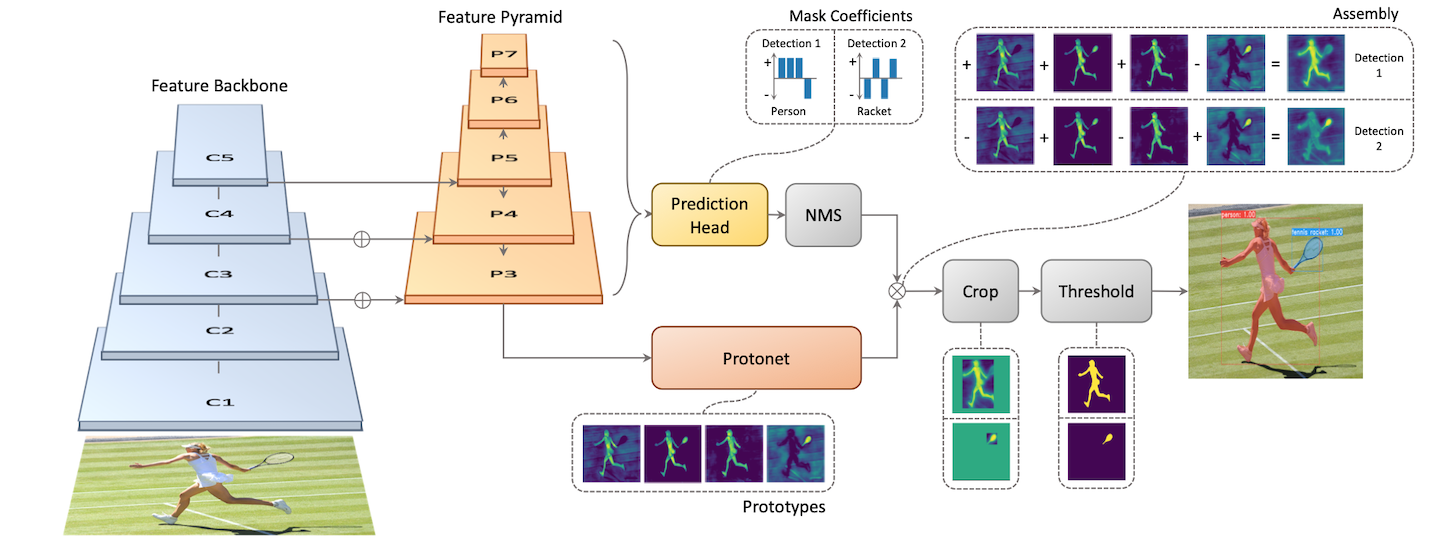
這個問題在 YOLACT (You Only Look At Coefficients) 26 得到解決。 YOLACT 一樣使用 ResNet、FPN 所組成,但是預測使用兩個分支,Prediction Head 生成 class + bbox + mask coefficients,Protonet 則會基於整張圖片生成 k 個 prototype mask。 作者嘗試過各種組合,認為 k = 32 效果最好。 每個 bbox 會對應到 k 個 mask coefficients,乘上 k 張 prototype mask 就可以線性組合成一張完整的實例分割。
在 YOLO 的後續版本(如 YOLOv8-seg)也開始引入這個概念,我們一樣可以透過 ultralytics 來快速測試其圖像分割的能力:
from ultralytics import YOLO
import cv2
# load the pre-trained model
model = YOLO('yolov8n-seg.pt')
# load the image
image_path = 'cat.jpg'
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# prediction
results = model.predict(source=image_rgb, task='segment')
result_image = results[0].plot()

結語
藉由卷積神經網路,電腦視覺成為人工智慧在過去十年的黃金應用。 從圖像分類到物件偵測與分割,這些技術不是垂直演化,而是並行發展、彼此互補。 隨著更巧妙的模型架構被提出來,特徵萃取與預測也變得更加精確、更加快速。 當影片能夠被即時分析,電腦視覺甚至開始跨足到車用輔助駕駛 (Advanced Driver Assistance Systems, ADAS) 和機器人視覺辨識的領域。
除了影像,卷積神經網路也被廣泛用於各種可以抽象拆解為二維特徵的問題。 例如 Google DeepMind 發表的 AlphaFold 27,就是將胺基酸之間的距離和接觸可能性表示成矩陣,再搭配領域知識來預測蛋白質結構。 雖然在 AlphaFold2 28 改轉向 Transformer 架構,但依舊保有 CNN 的設計理念。
另外,前文描述中基於 Encoder、Decoder 架構的模型,可以視為將資訊壓縮至低維度的潛在向量空間 (latent space),再進一步解碼出有意義的資訊(例如 bbox、mask)。 這種具備轉譯能力的模型,即是目前多模態生成式人工智慧 (Generative AI) 的前身。 比較有名的圖像生成模型有變分自編碼器 VAE (Variational Autoencoder) 29 和生成對抗網路 GAN (Generative Adversarial Network) 30。 前者能夠精妙學習圖像之間變化的特徵,後者能夠憑空生成相當逼真的影像。 礙於篇幅有限,這次就不多談,然而這些技術對於人工智慧如何理解影像資訊有著相當重要的意義。
然而影像終究是屬於比較稀疏且離散的資訊,透過 CNN 我們可以關注局部特徵,但對於連續有意義的資料(例如文章、股票、天氣)就沒那麼有用。 在下一個章節,我們會介紹如何處理序列資料,特別關注在深度學習是如何應用於自然語言上。
Next: DL 三部曲: to Speak (待更新)
Footnotes
Viso.ai, "The 100 most popular computer vision applications," URL: https://viso.ai/applications/computer-vision-applications/ ↩
Wikipedia, "Efficient coding hypothesis," URL: https://en.wikipedia.org/wiki/Efficient_coding_hypothesis ↩
Jieyu Zheng and Markus Meister, "The unbearable slowness of being: Why do we live at 10 bits/s?" Neuron 113 (2024): 192-204. ↩
Lowe, David G. "Object recognition from local scale-invariant features." Proceedings of the seventh IEEE international conference on computer vision. Vol. 2. Ieee, 1999. ↩
Dalal, Navneet, and Bill Triggs. "Histograms of oriented gradients for human detection." 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05). Vol. 1. Ieee, 2005. ↩
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems 25 (2012). ↩
Paddle Org., "零基礎實踐深度學習 - 4.1 常用的基礎網路模塊", URL: https://www.paddlepaddle.org.cn/tutorials/projectdetail/3493103 ↩ ↩2
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014). ↩
Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. ↩
He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. ↩ ↩2
Christian Szegedy, et al. "Inception-v4, inception-resnet and the impact of residual connections on learning." Proceedings of the AAAI conference on artificial intelligence. Vol. 31. No. 1. 2017. ↩
Ross Girshick, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. ↩ ↩2
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Fu, A.C. Berg, “SSD: Single Shot Multibox Detector”, Springer, Vol.9905, pp.21-37, 2016. ↩
J. Redmon, Santosh Divvala, R. Girshick, A. Farhadi, "You Only Look Once: Unified, Real-Time Object Detection," In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 779-788, 2016. ↩
Mark Everingham, et al. "The pascal visual object classes (voc) challenge." International journal of computer vision 88.2 (2010): 303-338. ↩
Tsung-Yi Lin, et al. "Microsoft coco: Common objects in context." European conference on computer vision. Cham: Springer International Publishing, 2014. ↩
R. Tedrake, "Robotic Manipulation: Perception, Planning, and Control." 2024. URL: https://manipulation.csail.mit.edu/segmentation.html ↩
Jonathan Long, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. ↩
Vincent Dumoulin, and Francesco Visin. "A guide to convolution arithmetic for deep learning." arXiv preprint arXiv:1603.07285 (2016). URL: https://github.com/vdumoulin/conv_arithmetic ↩
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Cham: Springer international publishing, 2015. ↩ ↩2
Michał Futrega, et al. "Optimized U-Net for brain tumor segmentation." International MICCAI brainlesion workshop. Cham: Springer International Publishing, 2021. ↩
Kaiming He, et al. "Mask r-cnn." Proceedings of the IEEE international conference on computer vision, 2017. ↩
Tsung-Yi Lin, et al. "Feature pyramid networks for object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. ↩
Shaoqing Ren, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems 28 (2015). ↩
Joseph Redmon, and Ali Farhadi. "Yolov3: An incremental improvement." arXiv preprint arXiv:1804.02767 (2018). ↩
Daniel Bolya, et al. "Yolact: Real-time instance segmentation." Proceedings of the IEEE/CVF international conference on computer vision. 2019. ↩ ↩2
Andrew W. Senior, et al. "Improved protein structure prediction using potentials from deep learning." Nature 577.7792 (2020): 706-710. ↩
John Jumper, et al. "Highly accurate protein structure prediction with AlphaFold." Nature 596.7873 (2021): 583-589. ↩
Diederik P. Kingma, and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013). ↩
Ian J. Goodfellow, et al. "Generative adversarial nets." Advances in neural information processing systems 27 (2014). ↩