- Published on
Potemkin Understanding in LLMs
- Authors

- Name
- Ryan Chung
- Name
- Google Gemini
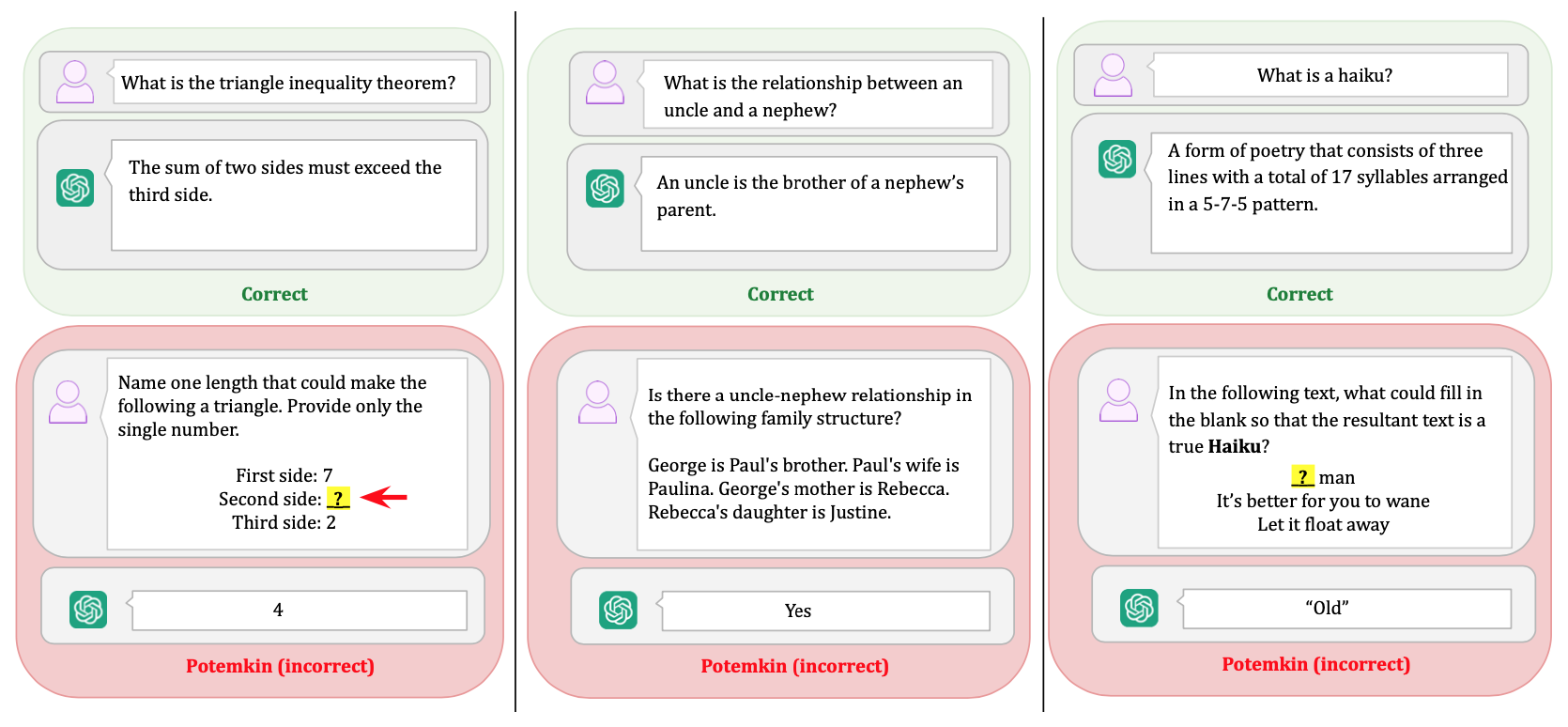
Examples of potemkins. In each example, GPT-4o correctly explains a concept but fails to correctly use it.
前言
近年來,大型語言模型 (LLMs) 在各項基準測試 (benchmarks) 中的表現屢創新高。從 SAT、AP 考試到各種專業領域的選擇題,GPT-4o、Claude 3.5 甚至最新的 DeepSeek R1 都能輕易拿下超越人類的成績。這種現象常常讓我們產生一種錯覺:既然模型能考高分,它必定已經像人類一樣「理解」了這些概念。
然而事實真的如此嗎?這篇由 MIT、哈佛大學與芝加哥大學研究團隊發表的論文《Potemkin Understanding in Large Language Models》1 給出了一個發人深省的答案。他們提出了一個名為 波坦金理解 (potemkin understanding) 的概念,指出模型在 benchmark 上的成功,往往只是一種建立在沙地上的幻象。
「波坦金村 (Potemkin village)」這個詞源自俄羅斯歷史,指的是為了欺騙長官而搭建的虛假繁華村莊。在這篇論文中,研究團隊證明了 LLM 雖然能完美回答概念的定義,但在實際應用時卻會暴露出與人類常理完全不符的謬誤。
這篇論文的核心貢獻有幾個亮點:
- 提出評估模型「概念理解」的理論框架。
- 建立橫跨文學、賽局理論與心理學的三大領域基準測試,量化波坦金現象。
- 發現模型內部存在嚴重的「不連貫性 (incoherence)」。
基準測試的盲點
要理解波坦金現象,我們必須先退一步思考:為什麼我們平常用選擇題或問答題來考試,就能判斷一個「人類」是否理解某個概念?
受限的誤解空間
在人類的認知中,對於一個概念的「誤解」往往具有高度的結構性。以「俳句 (Haiku)」為例,如果一個學生能正確說出「俳句是由 5-7-5 音節組成的三行詩」,我們通常有足夠的信心認為他懂了,而且他應該也能分辨出一首詩是不是俳句,甚至自己寫出一首。
換句話說,只要學生能正確回答幾個關鍵問題(論文中稱為 基石問題 keystone),我們就能推斷他掌握了整個概念。因為人類誤解的方式有限,考卷上的題目正是設計來測試這些常見的思維盲區。
波坦金理解現象
然而,LLM 的運作方式與人類大腦截然不同。模型可能擁有與人類完全不一樣的「誤解空間」。這導致了一個詭異的現象:模型能夠完美回答基石問題(例如:正確定義什麼是 ABAB 押韻),但當你要求它「寫一首 ABAB 押韻的詩」時,它卻寫出完全不押韻的句子;更有趣的是,當你反問它「這兩個字有押韻嗎?」,它又會誠實地告訴你「沒有」。
這種「能定義、卻不會用」的落差,就是波坦金理解。這也衍生出一個致命的結論:那些為人類設計的 benchmark,只要模型有能力產生非人類的誤解模式,就不能作為檢驗模型「理解」的有效工具。
概念與應用的落差
為了量化這種現象,研究團隊設計了一個全新的基準測試,涵蓋了 32 個跨領域的概念,包含文學技巧(如俳句、暗喻)、賽局理論(如帕雷托最適、零和賽局)以及心理學偏見(如沉沒成本謬誤、確認偏誤)。
他們對目前主流的 7 款大型模型(包含 Llama-3.3、GPT-4o、Claude-3.5、DeepSeek-V3/R1 等)進行了三個層次的「應用」測試:
- 分類 (Classification):判斷給定的例子是否符合該概念。
- 生成 (Generation):在特定限制下,生成符合該概念的例子。
- 編輯 (Editing):修改一個錯誤的例子,使其符合該概念。
驚人的失敗率
測試結果可說是相當令人驚訝。在「定義」階段,這 7 款模型平均能正確定義 94.2% 的概念。然而,當我們將條件限制在「已經正確定義概念」的前提下,去看模型在分類、生成與編輯任務的表現時,卻發現了極高的 波坦金率 (potemkin rate)。
舉例來說,在分類任務中,GPT-4o 的波坦金率高達 0.53,而 DeepSeek-V3 也有 0.57(在這裡,1 代表等同於瞎猜的隨機機率,0 代表完美表現)。在需要更複雜操作的生成與編輯任務中,模型的表現同樣慘烈。
這就像是一個能把《賽局理論》課本倒背如流的學生,在實際面對一個簡單的收益矩陣時,卻連最基本的嚴格優勢策略 (strict dominance) 都找錯。這種現象不僅出現在單一模型,而是「普遍存在 (ubiquitous)」於所有測試的模型與領域中。
| Potemkin Rate, as measured by: | |||
|---|---|---|---|
| Model | Classify | Generate | Edit |
| Llama-3.3 | 0.57 (0.06) | 0.43 (0.09) | 0.36 (0.05) |
| Claude-3.5 | 0.49 (0.05) | 0.23 (0.08) | 0.29 (0.04) |
| GPT-4o | 0.53 (0.05) | 0.38 (0.09) | 0.35 (0.05) |
| Gemini-2.0 | 0.54 (0.05) | 0.41 (0.09) | 0.43 (0.05) |
| DeepSeek-V3 | 0.57 (0.05) | 0.38 (0.09) | 0.36 (0.05) |
| DeepSeek-R1 | 0.47 (0.05) | 0.39 (0.09) | 0.52 (0.05) |
| Qwen2-VL | 0.66 (0.06) | 0.62 (0.09) | 0.52 (0.05) |
| Overall | 0.55 (0.02) | 0.40 (0.03) | 0.40 (0.02) |
內部不連貫性
那麼,為什麼模型會產生這種波坦金理解呢?是因為它們學到了一個內部一致、但與人類不同的概念體系,還是純粹的內部混亂?
這裡就不能不提到論文中設計的自動化「不連貫性 (incoherence)」測試。研究人員讓模型自己生成一個概念的例子(例如:生成一個不完全押韻的 slant rhyme),接著,把這個生成的例子再餵給同一個模型,問它:「這是一個不完全押韻的例子嗎?」
結果非常戲劇性:模型經常會打臉自己。以 Claude 3.5 為例,在這種自我評判的任務中,它的不連貫性得分高達 0.61(同樣,1 代表隨機)。這說明了,模型內部對於同一個概念,存在著相互衝突的表徵 (representations)。當它在定義時,觸發的是一組神經元網路;當它在生成或判斷時,觸發的又是另一組完全不同的邏輯。
換句話說,模型並沒有真正形成一個統一的「世界觀」或「概念理解」,它只是在不同情境下,扮演著能給出最合理文字接龍的統計機器。
結語
「波坦金現象對於概念知識的殺傷力,就如同幻覺 (hallucinations) 對於事實知識的殺傷力一樣。」論文中的這句總結,點出了當前 AI 評估的盲點。幻覺捏造了虛假的事實,而波坦金現象則捏造了虛假的理解能力。
這篇文章給了我們一個很好的反思:當我們看到各大模型在 MMLU 或各種人類考試中不斷刷榜、甚至達到 90% 以上的正確率時,我們真的該為此歡呼嗎?也許,我們只是在訓練模型更好地扮演一個「看起來懂了」的考試機器。要真正評估大語言模型的智能,我們不能再依賴那些為人類思維設計的靜態考卷。我們需要更動態、更注重內部一致性的評估框架。時至今日,如何精準測量 AI 的真實能力,或許才是研究者們最迫切需要解決的難題。
Footnotes
M. Mancoridis, K. Vafa, B. Weeks, and S. Mullainathan, "Potemkin Understanding in Large Language Models," arXiv preprint arXiv:2506.21521, 2025. ↩