- Published on
An AI system to help scientists write expert-level empirical software
- Authors

- Name
- Ryan Chung
- Name
- Google Gemini
前言
在科學研究中,我們經常遇到一個隱形的瓶頸:為了驗證假說或處理龐大的實驗數據,科學家們往往需要耗費數月甚至數年的時間去手動撰寫和調校軟體。從 1998 年的密度泛函理論(Density Functional Theory)、2013 年的分子動力學模擬,再到 2024 年以 AlphaFold 拿下諾貝爾化學獎的蛋白質結構預測,這類為了最大化某種「觀測品質指標」而設計的 「經驗軟體 (empirical software)」,早已經成為現代科學突破的核心基礎。 然而,手寫這類軟體不僅耗時,而且在面對極度複雜的科學問題時,開發者往往只能憑直覺或經驗來做設計抉擇,很難窮舉所有可能的演算法組合。
為了解決這個痛點,Google Research 與 DeepMind 團隊近期發表了這篇名為《An AI system to help scientists write expert-level empirical software》的論文。他們提出了一套基於大型語言模型 (LLM) 與 樹狀搜尋 (Tree Search, TS) 的 AI 系統。這套系統能夠自動探索、重組文獻中的研究靈感,並針對特定的科學評估指標不斷自我進化,最終寫出超越人類專家水平的軟體程式碼。
這篇論文最吸引人的地方在於,它不僅僅是一個「寫程式的 AI」,它更像是一個不知疲倦的虛擬科學家,能在單細胞基因體學、流行病學預測、地理空間分析等多個領域,從零開始打造出突破現有基準測試 (benchmark) 的解決方案。
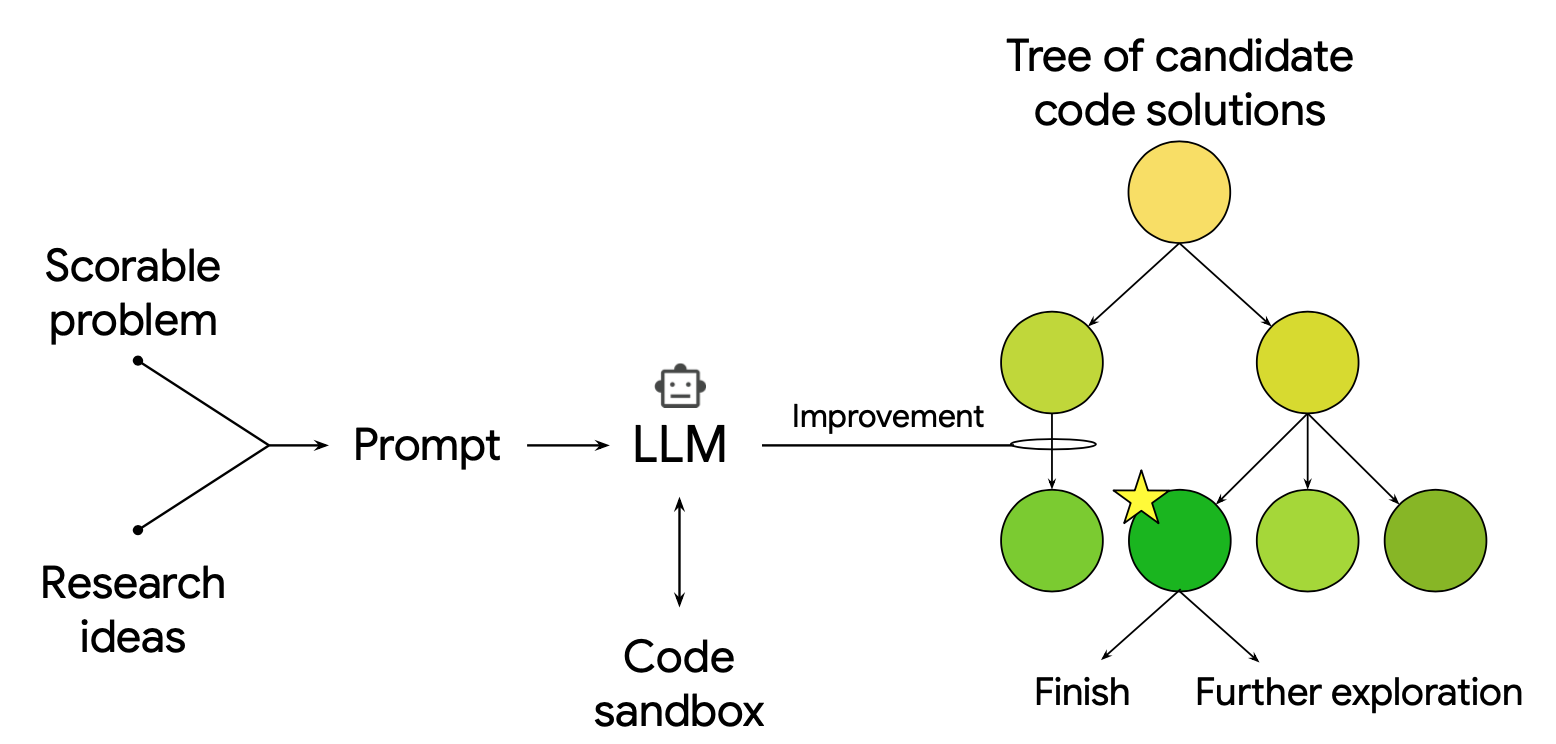
核心機制:把寫程式變成一場有分數的樹狀搜尋
如果說 LLM 像是擁有了全世界知識的圖書館員,那這套系統就是給這個圖書館員配備了一個極其理性的實驗室主管。 這套 AI 系統的核心邏輯,是把「撰寫科學軟體」轉化為一個 「可評分任務 (scorable task)」。只要你能定義出一個明確的品質指標(例如:預測準確率、誤差值),這個系統就能不斷地進行試錯與優化。
基於 PUCT 的樹狀搜尋
作者們參考了 AlphaZero 2 3 的架構,使用了一種名為 PUCT (Predictor + Upper Confidence bound applied to Trees) 的樹狀搜尋演算法。傳統的 Genetic Programming 4 是透過隨機突變來修改程式碼,而這套系統則是讓 LLM 扮演「智能突變器」的角色。
具體的運作流程如下:
- 輸入提示:系統會將任務描述、評估指標與相關數據交給 LLM。
- 生成候選解:LLM 生成出初步的 Python 程式碼,並在沙盒 (sandbox) 中執行、評分。
- 節點擴展與回溯:在樹狀結構中,系統會根據每個程式碼節點的得分,平衡「探索 (exploration)」與「利用 (exploitation)」,選擇最有潛力的節點讓 LLM 進行下一步的改寫與優化。
換句話說,LLM 不再是「一次性生成 (one-shot generation)」就結束了,而是在一個有目標引導的迴圈中,不斷看著前一次的執行結果(與錯誤日誌)來爬山 (hill climbing),直到找到最佳解。
知識注入與點子重組
除了盲目搜索,科學研究最重要的一環是站在巨人的肩膀上。這套系統最亮眼的功能之一,是它能夠攝取外部的研究點子 (research ideas)。
科學家可以直接把相關論文的摘要、教科書概念 5,甚至是用 Google Deep Research 6 或 AI co-scientist 7 找出來的前沿想法,當作提示詞注入給 LLM。更驚人的是,系統還能自動進行重組:把方法 A 的特長跟方法 B 的特長融合在一起。這就像是讓 AI 讀完了所有頂會論文後,自行把不同流派的招式揉合成一套全新的絕學。
實驗結果:在多個領域擊敗人類專家
為了驗證這套系統的極限,研究團隊不僅在 Kaggle 競賽中測試,更挑選了六個進展緩慢但極具科學價值的領域進行挑戰。結果可說是相當令人驚艷。
1. 流行病學:超越 CDC 的 COVID-19 預測模型
在預測美國 COVID-19 住院人數的任務中,這套系統與美國 CDC 官方的 CovidHub 8 進行了較量。CovidHub 匯集了數十個頂尖學術機構的預測模型,並組合成一個被視為黃金標準的 Ensemble 模型。
然而,AI 系統透過自動重組與深度研究,竟然生成了 14 個在加權區間得分 (Weighted Interval Score, WIS) 上超越 CDC Ensemble 的全新模型。其中表現最好的策略,往往是結合了基於歷史氣候的基礎模型 (如 CMU-climate_baseline) 與強大的機器學習模型 (如 UMass-gbqr),完美展現了重組的威力。
2. 生物資訊學:單細胞 RNA 定序資料整合
在處理單細胞 RNA 定序 (scRNA-seq) 9 數據時,消除不同實驗室之間的「批次效應 (batch effects)」是一個極度困難的挑戰。
系統在 OpenProblems 10 的基準測試中,不僅成功重現了現有的頂尖演算法,還自行發明了 40 種全新的資料分析方法,這些方法的表現全部超越了原本霸榜的人類開發模型。例如,表現最好的 BBKNN (TS) 11 模型,就是 AI 自行決定把 ComBat-corrected 12 PCA 降維技術與 BBKNN 演算法結合,這在原本的文獻中是前所未見的。
3. 神經科學與時間序列預測
在斑馬魚全腦神經活動預測 (ZAPBench) 13 任務中,系統生成的模型在「多步預測」上擊敗了所有現有的基準,甚至是極度耗費算力的 3D 影片預測模型。而且,AI 生成的模型在單張 T4 GPU 上只要訓練不到兩小時,相比之下,原本的 SOTA 模型需要 16 張 A100 訓練 36 小時。這差距確實有點戲劇性。
除此之外,在地理空間分析 (衛星影像的語意分割) 14、一般時間序列預測 (GIFT-Eval) 15,甚至是在數值分析 (計算極度困難的積分) 上,這套系統都交出了超越現有標準套件 (如 scipy.integrate.quad 16) 的完美成績單。
結語
這種結合 LLM 與樹狀搜尋的 AI 系統相當有潛力。 對於科學家而言,它將實驗探索週期從數週或數月縮短到數小時或數天。 這意味著研究人員可以更快地測試複雜假設、篩選數十種不同的方法,並將更多精力投入到結果分析和新概念發想上。 任何可以量化為「品質分數」的科學問題——從藥物標靶發現到氣候建模——都可能因這個系統而迎來革命性的加速。
儘管這個 AI 系統展示了傑出的成果,我們仍需誠實面對其侷限性。 首先,它僅限於解決那些可以被明確定義的可評分任務,對於缺乏清晰量化指標或需要大量開放式探索的科學問題則難以適用。 其次,如同傳統的 Genetic Programming 4 和 AutoML 17,系統的有效性依賴於搜索策略和 LLM 整合外部知識的能力。
然而,Google 開發的這個 AI 系統依然在科學軟體領域中畫下了一個里程碑。 它證明了 AI 能夠系統性地創新、組合和優化專家級的解決方案,並在數十個關鍵的科學難題上超越了人類專家的成果,大幅縮短了科學探索的耗時。 研究人員相信,至少在可評分領域,科學進步正處於革命性加速的前夕。 未來,AI 將不再只是科學家的工具,更可能成為一位不知疲倦協作者,極大地推動人類知識的疆界。
Footnotes
E. Aygün et al., “An AI system to help scientists write expert-level empirical software,” Sep. 08, 2025, arXiv:2509.06503. ↩
D. Silver et al., “Mastering the game of Go with deep neural networks and tree search,” Nature, vol. 529, pp. 484–489, 2016. ↩
D. Silver et al., “Mastering the game of Go without human knowledge,” Nature, vol. 550, pp. 354–359, 2017. ↩
J. R. Koza, “Genetic programming as a means for programming computers by natural selection,” Stat. Comput., vol. 4, pp. 87–112, 1994. ↩ ↩2
B. Romera-Paredes et al., “Mathematical discoveries from program search with large language models,” Nature, vol. 625, pp. 468–475, 2024. ↩
Google. Gemini Deep Research (2025). URL https://gemini.google/overview/deep-research/?hl=en. ↩
J. Gottweis et al., “Towards an AI co-scientist,” arXiv preprint arXiv:2502.18864, 2025. ↩
Centers for Disease Control and Prevention. COVID-19 forecast hub (2025). URL https://github.com/cdcgov/covid19-forecast-hub?tab=readme-ov-file. ↩
Stuart, T. & Satija, R. Integrative single-cell analysis. Nat. Rev. Genet. 20, 257–272 (2019). ↩
Luecken, M. D. et al. Defining and benchmarking open problems in single-cell analysis. Nat. Biotechnol. 43, 1035–1040 (2025). ↩
K. Polański et al., “BBKNN: fast batch alignment of single cell transcriptomes,” Bioinformatics, vol. 36, pp. 964–965, 2019. ↩
W. E. Johnson, C. Li, & A. Rabinovic, “Adjusting batch effects in microarray expression data using empirical Bayes methods,” Biostatistics, vol. 8, pp. 118–127, 2007. ↩
J.-M. Lueckmann et al., “ZAPBench: a benchmark for whole-brain activity prediction in zebrafish,” arXiv preprint arXiv:2503.02618, 2025. ↩
Z. Shao, K. Yang, & W. Zhou, “Performance evaluation of single-label and multi-label remote sensing image retrieval using a dense labeling dataset,” Remote Sens., vol. 10, p. 964, 2018. ↩
T. Aksu et al., “GIFT-Eval: a benchmark for general time series forecasting model evaluation,” arXiv preprint arXiv:2410.10393, 2024. ↩
R. Piessens et al., QUADPACK: a subroutine package for automatic integration. Springer-Verlag, 1983. ↩
F. Hutter, L. Kotthoff, & J. Vanschoren, Automated machine learning: methods, systems, challenges. Springer Nature, 2019. ↩