- Published on
Potemkin Understanding in LLMs
- Authors

- Name
- Ryan Chung
- Name
- Google Gemini
M. Mancoridis, K. Vafa, B. Weeks, and S. Mullainathan, “Potemkin Understanding in Large Language Models,” in Proceedings of the 42nd International Conference on Machine Learning, Vancouver, Canada, 2025. https://arxiv.org/abs/2506.21521
前言
想像一下,你問最新的 GPT-4o:「什麼是 ABAB 押韻格式?」 它給出了一個清晰、完美的解釋:「第一行與第三行押韻,第二行與第四行押韻」。你印象深刻,覺得它真的「懂」了。 接著,你請它用這個格式完成一首詩,它卻給出完全不押韻的詞語。 更奇怪的是,當你反問它「你給的詞押韻嗎?」它竟然回答「不押韻」。
這到底是怎麼回事? 這種看似理解、實則不然的矛盾現象,正是麻省理工學院、哈佛大學和芝加哥大學的研究人員在一篇新論文中揭示的核心問題。 他們將這種現象命名為 「波坦金式理解」(Potemkin Understanding)。 這篇文章將帶你深入了解這個 AI 世界的「美麗謊言」,探討我們現有的評估方式為何會失效,以及這對我們與 AI 的未來互動意味著什麼。
為何我們總是以為 AI 很懂?現行評估方式的盲點
長久以來,我們評估大型語言模型(LLM)能力的方式,很大程度上是沿用評估人類的標準,例如讓它們參加 AP 考試、醫學測驗或數學競賽。 這種方法之所以對人類有效,是因為人類的「誤解」是有跡可循、有結構的。 例如,一個學生如果誤解了物理公式,他在所有相關題目上的錯誤都會呈現出某種一致的模式。 因此,設計精良的考卷可以有效地篩選出真正理解概念的人。
然而,這篇研究提出了一個關鍵的警示:我們不能假設 AI 的「思考」模式和人類一樣。 如果 LLM 的「誤解」方式與人類大相徑庭,那麼專為人類設計的測驗就可能完全失效。 AI 可能會找到一種非人類的「捷徑」來答對問題,讓我們誤以為它具備了深層次的理解,而實際上它只是在表演一場華麗的戲。 這就是「波坦金式理解」的來源——這個詞源於歷史上為了取悅君主而搭建的「波坦金村莊」,它們只有光鮮的外表,背後卻空無一物。
揭穿騙局:研究人員如何「釣」出 AI 的真實理解程度
為了量化這種虛假的理解,研究團隊設計了兩套巧妙的實驗流程。
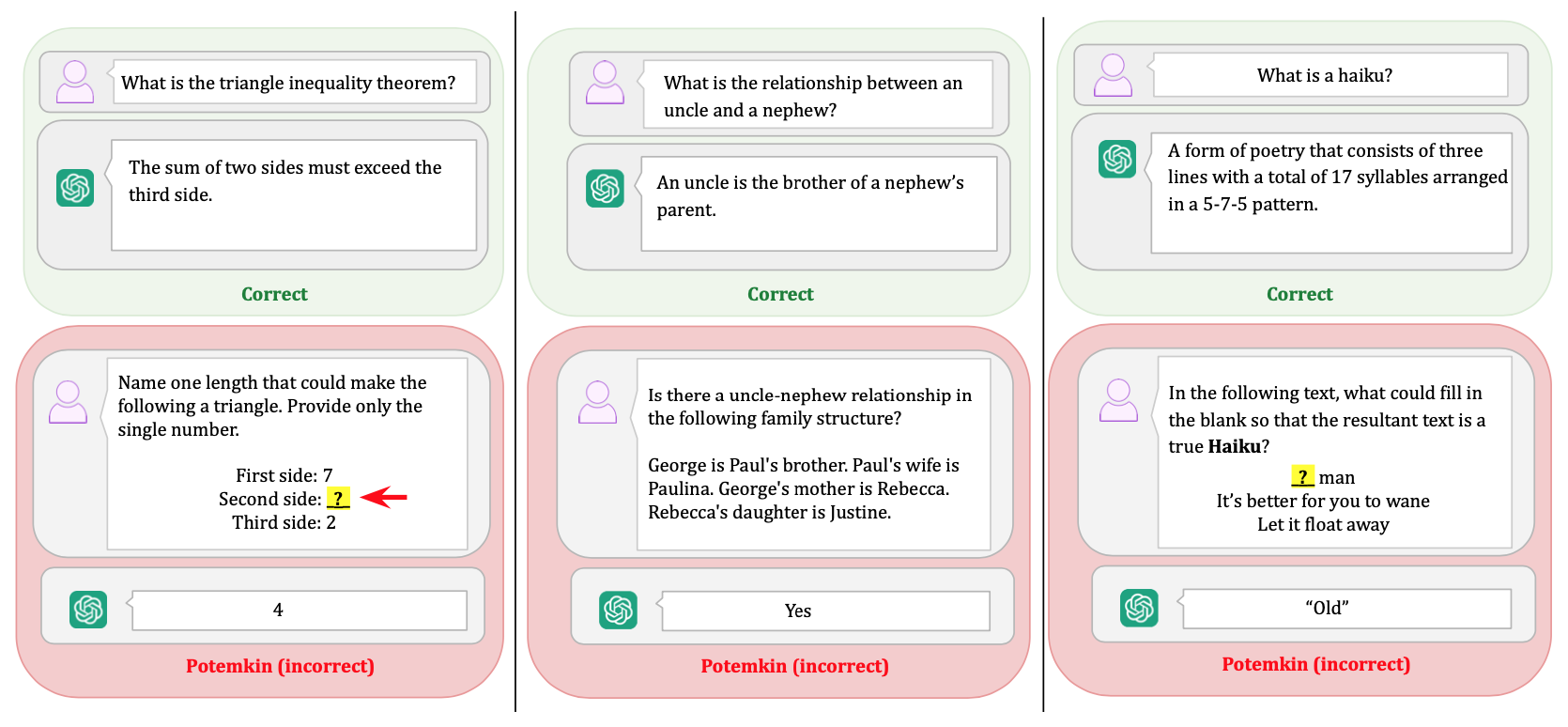
第一套流程像是為 AI 設計的一場深度「口試 + 實作」測驗。 研究人員橫跨三個截然不同的領域——文學技巧、賽局理論和心理學偏誤——挑選了 32 個核心概念。 他們對 7 個主流 LLM(包括 Llama-3.3、GPT-4o、Claude-3.5 等)進行測試。測試分為兩步:
- 概念解釋:首先,要求模型定義一個概念,例如什麼是「俳句」(haiku) 或「沉沒成本謬誤」(sunk cost fallacy)。這就像是考試中的「名詞解釋」題。
- 概念應用:如果模型答對了定義,接著就要在三個實際任務中應用這個概念:分類(判斷一個例子是否符合該概念)、生成(按要求創造一個新例子)和 編輯(修改一個例子使其符合或不符合概念)。
第二套流程則更進一步,讓 AI 自己「監督」自己,就像是讓它檢查自己的作業,從而暴露其內在的矛盾。
AI 的驚人真相:三大核心發現
經過對超過 3,000 個數據點的分析,研究結果揭示了 LLM 普遍存在的「波坦金式理解」。
發現一:「能說不能做」— 定義與應用的巨大鴻溝
研究發現,LLM 在定義概念方面表現近乎完美,準確率高達 94.2%。 然而,一旦要求它們應用這些概念,表現便急轉直下。 研究人員將這種「答對了定義題,卻搞砸了應用題」的情況定義為 「波坦金率」(potemkin rate)。
結果顯示,所有模型在所有任務中都存在很高的波坦金率。 例如,在分類任務中,模型的平均波坦金率(可視為在理解前提下的錯誤率)高達 55%。 這意味著,即使模型能完美背出規則,它在實際判斷時,有一半以上的機率會出錯。 這個問題並非特定模型的瑕疵,而是普遍存在於我們測試的所有頂尖模型中。
| Potemkin Rate, as measured by: | |||
|---|---|---|---|
| Model | Classify | Generate | Edit |
| Llama-3.3 | 0.57 (0.06) | 0.43 (0.09) | 0.36 (0.05) |
| Claude-3.5 | 0.49 (0.05) | 0.23 (0.08) | 0.29 (0.04) |
| GPT-4o | 0.53 (0.05) | 0.38 (0.09) | 0.35 (0.05) |
| Gemini-2.0 | 0.54 (0.05) | 0.41 (0.09) | 0.43 (0.05) |
| DeepSeek-V3 | 0.57 (0.05) | 0.38 (0.09) | 0.36 (0.05) |
| DeepSeek-R1 | 0.47 (0.05) | 0.39 (0.09) | 0.52 (0.05) |
| Qwen2-VL | 0.66 (0.06) | 0.62 (0.09) | 0.52 (0.05) |
| Overall | 0.55 (0.02) | 0.40 (0.03) | 0.40 (0.02) |
發現二:AI 的「內心矛盾」— 普遍存在的內部不連貫性
你可能會想,AI 是不是只是理解得有點偏差,但至少它的理解是「一致」的?研究的第二個發現打破了這個幻想。 研究人員進行了一項 「不連貫性」(incoherence) 測試:他們先讓模型生成一個概念的例子(例如,一個「斜韻」slant rhyme),然後在一個全新的對話中,把模型自己生成的例子拿回去問它:「這是斜韻嗎?」。
結果令人驚訝。在很多情況下,模型會否定自己剛剛給出的答案。 這種前後矛盾的現象表明,LLM 的問題不僅僅是「理解錯誤」,而是其內部對同一個概念的表述可能是混亂和衝突的。 換句話說,它對一個概念的「理解」在不同時間、不同情境下可能會完全不同。
發現三:擴充題庫也沒用?「波坦金」問題根深蒂固
另一個令人擔憂的發現是,這種淺層理解的問題似乎根深蒂固。 研究團隊進行了一項模擬分析:如果我們不僅用「定義」作為測驗標準,還加上好幾個「應用題」作為門檻(也就是擴大所謂的 「基石問題集」(keystone set)),AI 的表現會不會變好? 結果顯示,即使提高了「入門考試」的難度,AI 在後續更多應用題上的表現提升也相當有限。 這暗示著,簡單地用更多題目來「訓練」或「測驗」AI,可能無法解決這個根本性的理解缺陷。
這對我們意味著什麼?實際生活的啟示
這項研究不僅是學術界的探討,更對我們的日常生活和工作帶來深遠的啟示:
對一般使用者:當你使用 AI 尋求建議時——無論是法律諮詢、醫療資訊還是寫作輔助——請保持警惕。一個能流暢解釋複雜概念的 AI,不代表它能可靠地應用這些知識。它的自信可能只是一種假象。
對開發者與企業:單純追求在排行榜上獲得高分是危險的。這項研究提供了一套框架和工具,幫助我們更深入地評估模型的真實能力,避免在開發和部署高風險應用(如自動駕駛、金融交易)時,被表面的高分所蒙蔽。
對教育與未來:我們需要重新思考如何評估「智能」。如果連最先進的 AI 都可能陷入這種「懂其然,卻不懂其所以然」的困境,那麼我們在教育下一代時,更應強調 真正的概念理解,而非機械式的記憶與應答。
研究的下一步:從揭露問題到解決問題
研究人員坦言,他們目前的基準數據集雖然廣泛,但還未能涵蓋所有可能的概念和問題類型。 未來的研究需要建立更全面的測試工具,來識別更多潛在的「波坦金」現象。
更重要的是,下一步的挑戰將是開發出能夠 減少甚至消除「波坦金式理解」 的訓練方法和模型架構。 這項工作不僅是為了打造更聰明的 AI,更是為了確保我們能與一個真正可靠、值得信賴的 AI 共同前進。
總結來說,「波坦金式理解」的研究為我們敲響了一記警鐘。 它揭示了大型語言模型光鮮能力背後的深刻缺陷:一種非人類的、難以預測的、且充滿內在矛盾的「理解」方式。 下次當你對 AI 的博學讚嘆不已時,不妨多問一句:這份聰明,究竟是深刻的理解,還是一座精心搭建的華麗村莊?