- Published on
DeepSeek V3 & R1 論文研究
- Authors

- Name
- Ryan Chung
前言
2025 年 1 月 20 日,中國 幻方量化 (High-Flyer) 旗下的 AI 研究公司 深度求索 (DeepSeek) 發表 DeepSeek R1 模型 2, 其優異的性能與極高的性價比震驚整個產業圈,甚至造成美股震盪。Nvidia 直接在一天內大跌 17%,損失近 6 千億美元,創下歷史紀錄 3。
一時之間所有人都在問:「DeepSeek 到底是誰?模型是真的假的?」AI 儼然成為過年的熱門話題。 就結論而言,DeepSeek 確實做到了幾項不容忽視的壯舉:
- 完全開源。 要知道,開源的大型語言模型不少,例如 Meta LLaMA、Mistral AI 等,但是其效能都比不上目前 Tier1 的閉源模型,如 GPT-o1、Claude 3.5 sonnet。 DeepSeek 除了開源模型本身,也提供極其便宜的 API 服務,讓原本由美國科技巨頭獨霸的商業應用突然被東方神秘力量給打破。
- 成本極低。 中國受到美國晶片禁令的影響,只能購買降規版的 Nvidia H800 GPU。然而 DeepSeek 用 2048 個 H800 打造出 GPU 叢集,僅僅用 $5.576M (以 $2/hr 計算) 就訓練出 DeepSeek V3 4。 一般來說,LLM 的訓練費用動輒千萬美金,模型 pre-training 完全是科技巨頭壟斷的領域。 DeepSeek 的發表等於給所有科技公司自行研發 LLM 的一線曙光。
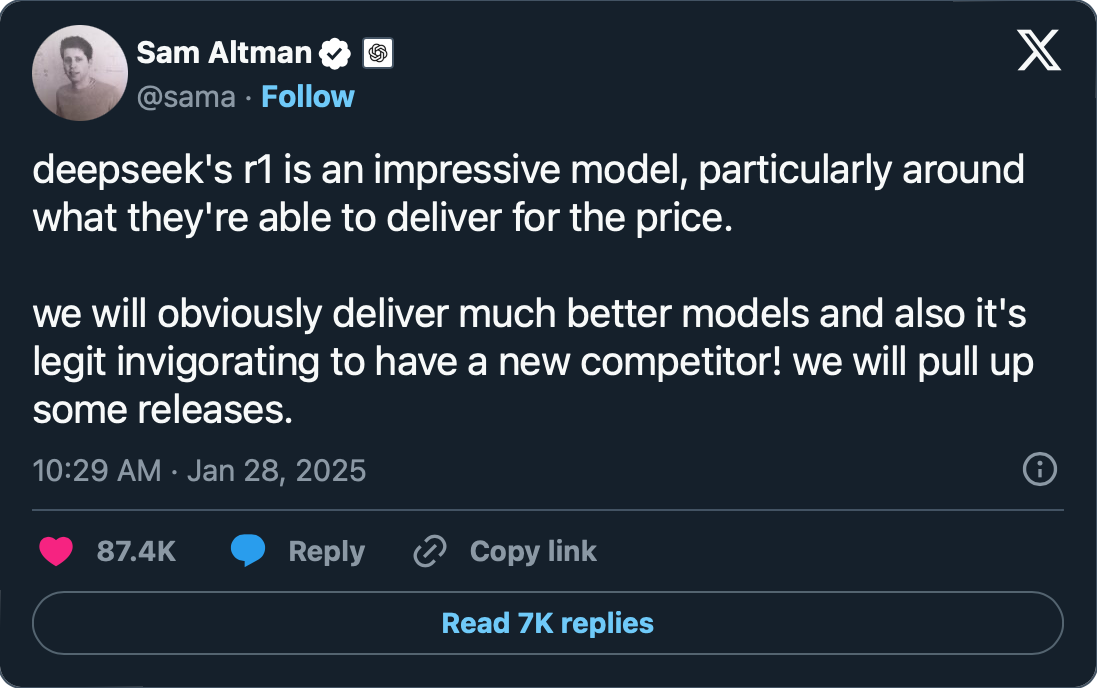
除此之外,DeepSeek 在模型架構與訓練方式上亦融合諸多技術,讓這一切看似不可能的任務變得可能。 雖然中國政府對於言論審查的要求,讓 DeepSeek 在回答敏感話題的能力比較受限。 純粹就技術面來看,這依舊是近來相當值得關注的研究成果,就連 OpenAI 的執行長 Sam Altman 都忍不住讚嘆 5。
DeepSeek V3
其實早在 2024 年 12 月底,DeepSeek 就發布 V3 模型 6,當時的結果已表明 DeepSeek V3 有超越 GPT-4o 的能力 4。 只是大家認為中國公司又是從 OpenAI 蒸餾 (distillation) 出新模型,這件事有點不了了之,論文內容也沒有受到太大關注。 直到推理模型 DeepSeek R1 發布,才讓人們重新關注起通用模型 V3,這個展開確實有點戲劇性。
根據官方論文,DeepSeek V3 有幾個主要貢獻:
- 模型架構:
- Mixture-of-Experts (MoE) with auxiliary-loss-free strategy for load balancing
- Multi-head Latent Attention (MLA)
- Multi-Token Prediction (MTP)
- 訓練與處理:
- FP8 mixed precision training framework
- DualPipe algorithm and efficient cross-node communication
- Distill reasoning capability from DeepSeek R1
雖說本質仍脫離不了 Transformer 的框架,但透過模型細節的調整、技術的創新以及硬體核心的優化,從多個角度切入並整合,才有今日的 DeepSeek V3。
DeepSeekMoE
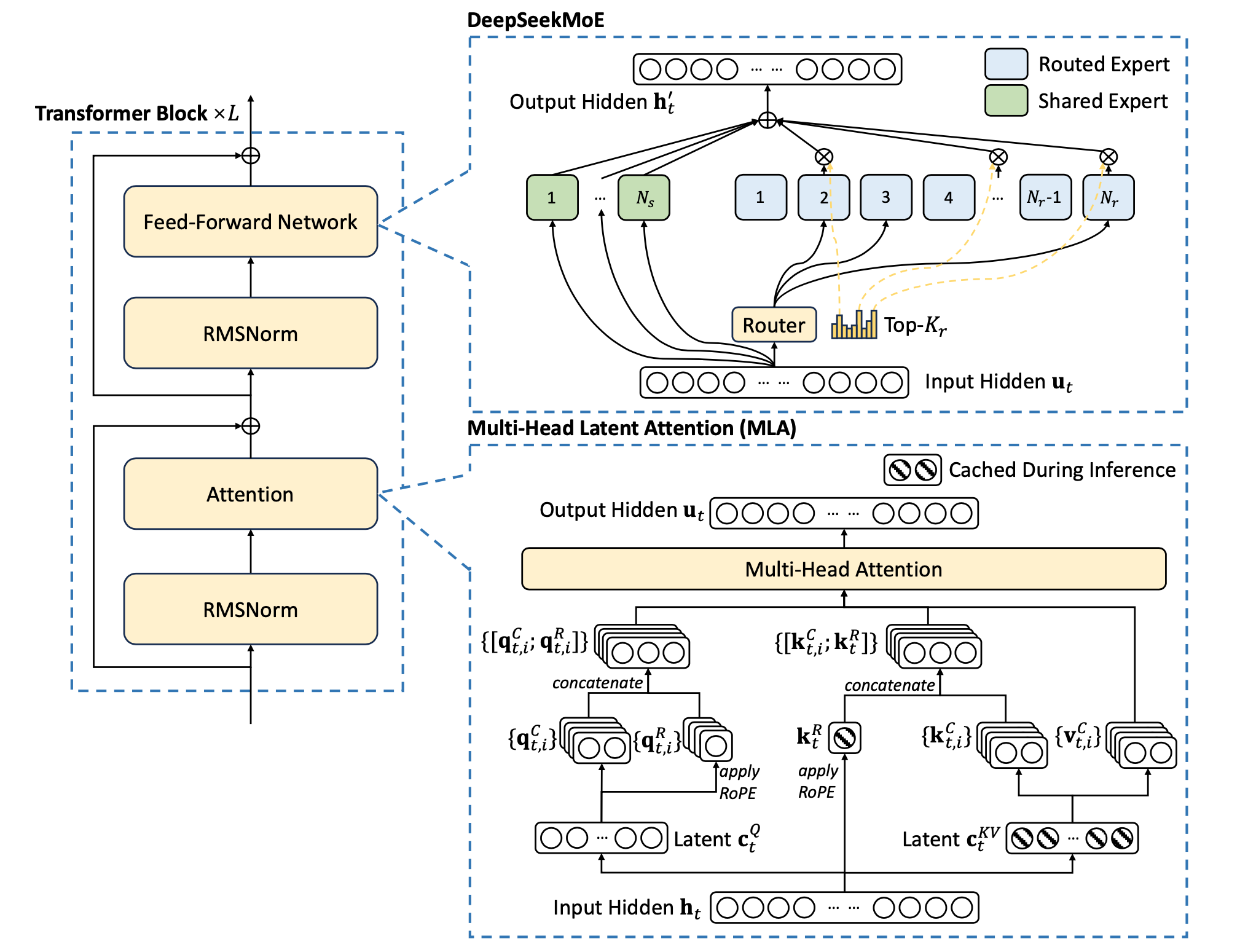
Mixture-of-Experts (MoE) 其實不是什麼新東西 7,其原理就是將原本以 dense layer 為主的 Feed-Forward Network (FFN) 換成多個小型模塊,將任務分批丟給它們運算。 這些小模塊經過訓練後,可以視為不同領域的專家 (expert),他們參數少、習得的東西有限,但是可以更有效的解決特定任務。 所以在將 token 丟給 experts 前必須有個 gating 機制來決定要將其丟給誰,最簡單就是計算 affinity score 做 top-K 排序,也就是看哪位專家最適合就丟給誰。 這樣最大的問題是 load unbalance,有些專家可能會被過度使用,有些則幾乎沒有機會發揮,造成運算資源的浪費。
DeepSeekMoE 採用的策略是將專家切的更多更細,並引入一個 shared expert 來處理比較通用的基礎知識。 對於每個 token,總共 256 個 routed experts,一次只會選中 8 個,也就是會有 1+8=9 個專家。 DeepSeek V3 總共 671B 個參數,每次只會啟動 37B 個參數,大幅增加運作效率。
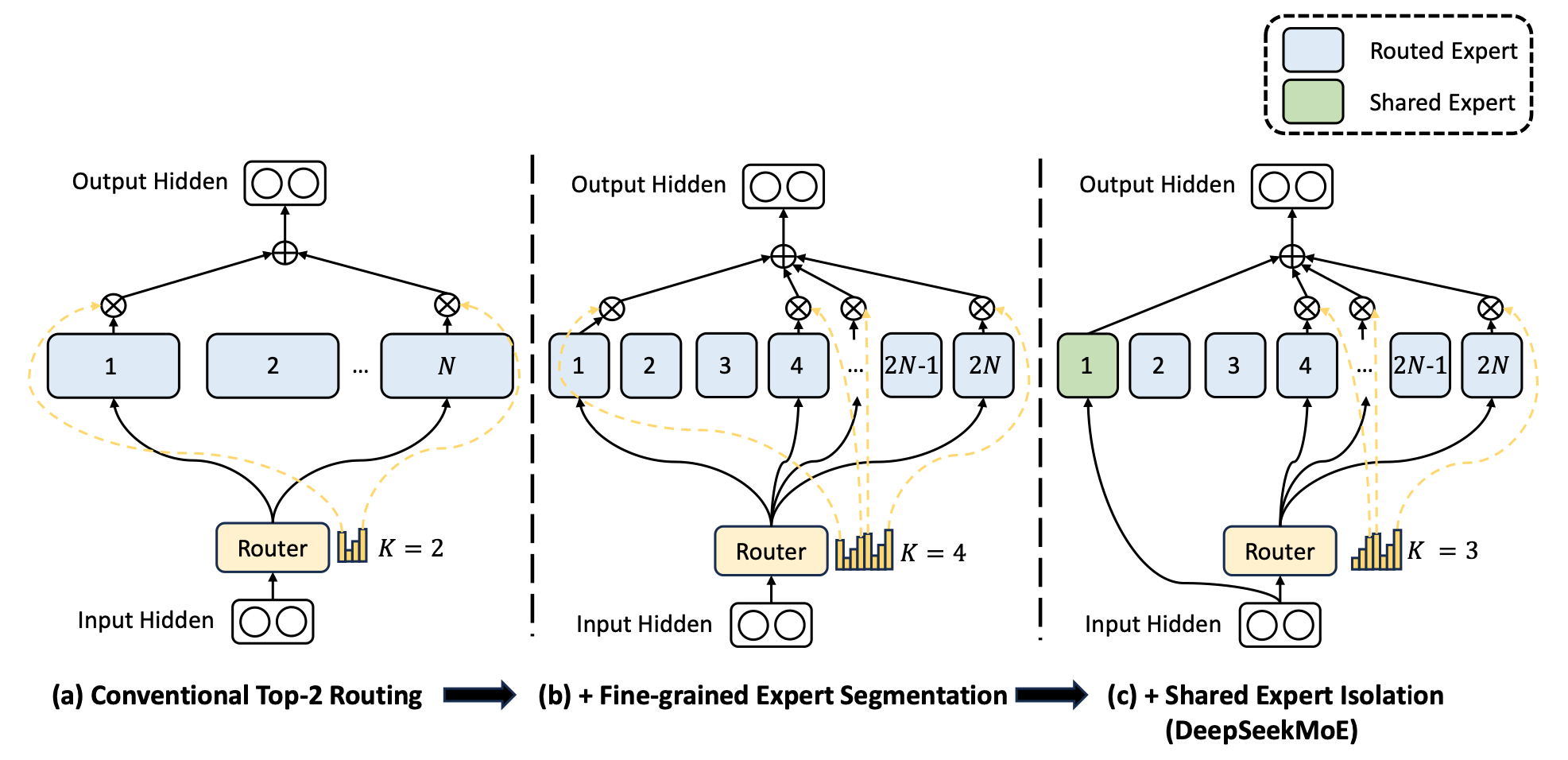
然而這些技術都是從 DeepSeek V2 繼承下來的,V3 最大的改變是在於 auxiliary-loss-free 的策略。 傳統 load balancing 的方式是透過輔助損失來調整,但這樣會增加訓練時間。 DeepSeek V3 取消輔助損失,改而將每一個專家的 affinity score 加上一個 bias,讓其隨著該專家的使用率進行動態調整。 這種作法有點類似 schedule 的 aging 機制,以此來簡單平衡專家的使用率。
Multi-Head Latent Attention
眾所皆知,Transformer 的核心在於 Multi-Head Attention 機制,而如何有效地計算 attention 一直是一個學問。 一些方法如 Grouped-Query Attention (GQA)、Multi-Query Attention (MQA),都是將不同 head 的 key、value 做整合,以期減少記憶體用量。 DeepSeek 採用創新的 MLA 機制,中心思想跟 LoRA 很像,都是將矩陣做低秩投影 (low-rank projection),以減少 KV cache 的大小。
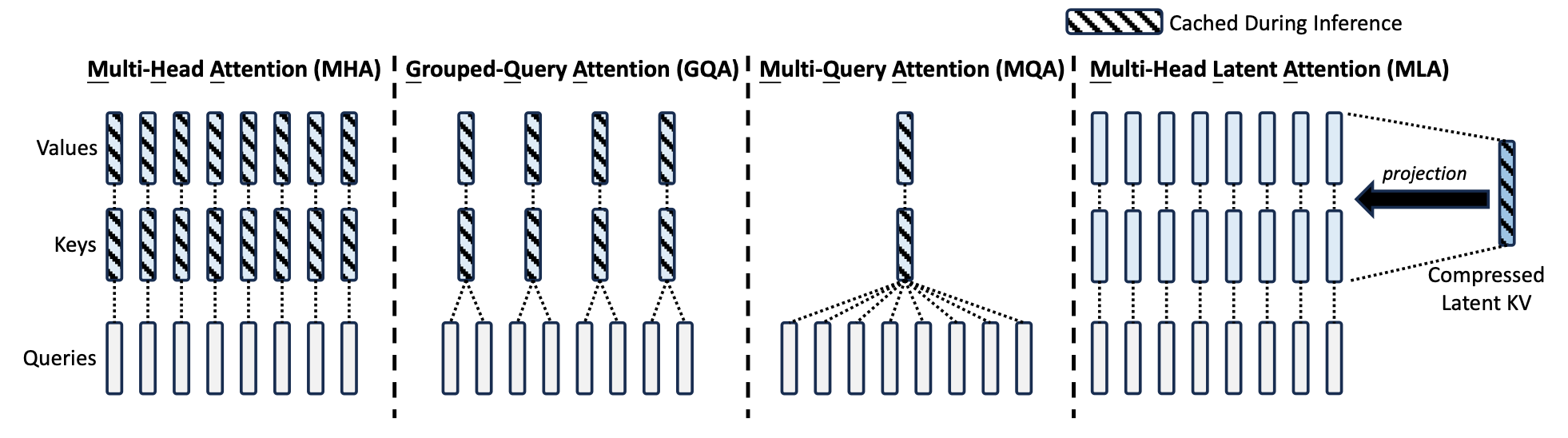
以下面為例,原先我們會從每個 input token 來計算 query、key、value,然後再做 attention 運算。
MLA 將原本的 合併成降維的 compressed latent vector ,再透過 還原出 key、value。
有趣的是,因為我們會將 query * key 取 softmax 後再乘上 value,所以 可以被 合併、 可以被 合併(如下列公式)。 最終我們只需要計算並儲存降維後的 即可。 在 DeepSeek V2 的論文中,MLA 可以有效降低 KV cache 93.3% 的記憶體空間,同時提升表現結果 9。
除了 key-value 外,query 也可以做低秩投影。 但是旋轉矩陣 Rotary Position Embedding (RoPE) 就無法這樣操作,必須另外做特殊處理。 這部分細節就留給有興趣的人自行去研究。
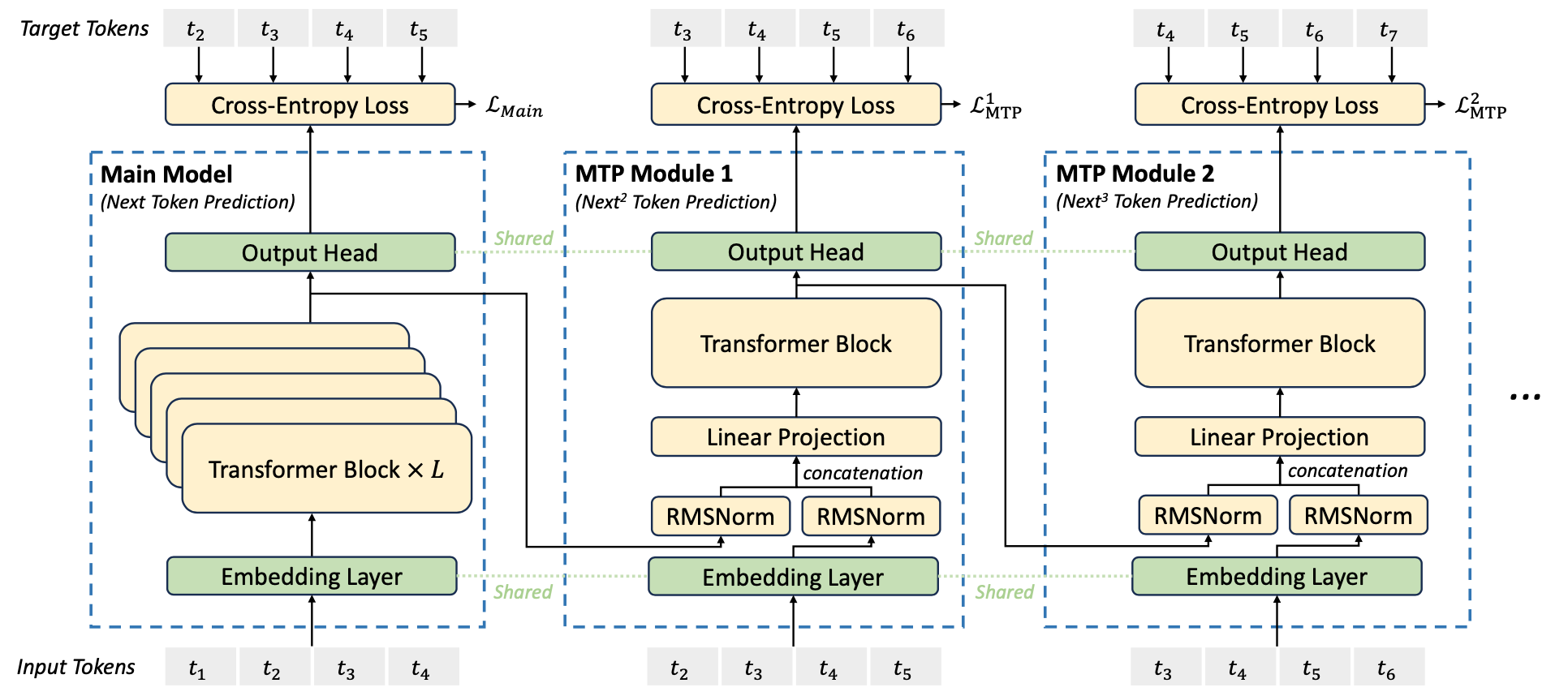
Multi-Token Prediction
MTP 也不是新技術,最早在 2024 年 Meta 就提出相關論文(好像也沒多早)10。 簡單來說,我們可以透過一些方式先「快速」預測多個 token,而不是一次只序列生成一個。這麼做有什麼好處呢? 當我們預測出未來時,就可以將這幾個未來 token 串接起來,用主要模型平行運算出後面幾步 token,再以此進行校正。 如果這些預測不準確,我們最差也能正常推論出一個 token;如果預測準確 (eg, N steps),我們最多可以直接生成 N+1 個 token。 這就叫做 speculative decoding,用在 LLM 非常適合。
DeepSeek 使用什麼方式來預測呢?那就是「更小的模型」,具體而言是單層 Transformer block。 這些小型的 MTP 模組串接在主要模型旁,維持 causal chain 的方式來預測 token。 由 token 2 預測出 token 3,再由 token 3 預測出 token 4,然後把結果送回主要模型進行校正。 在論文中提及,這些預測模型的正確率高達 85-90%,使得整體推論速度可以提升 1.8 倍。
FP8 Mixed Precision Training
針對 LLM,我們會通常會採用 FP32、BF16 浮點數來訓練,或是利用量化技術 (quantization) 來降低精度至 8bit、4bit。 DeepSeek V3 採用混合精度訓練,對於主要運算 General Matrix Multiplication (GEMM) 使用 FP8 精度, 包含正向傳遞 (forward propagation) 與反向傳遞 (activation backward pass)、 (weight backward pass); 對於部分模組則維持原始精度,如 input 與 output embedding、MoE gating modules、normalization operators、attention operators。 原始論文聲稱對比 BF16 baseline,相對誤差損失低於 0.25%,代表這個策略是有效且可靠的。
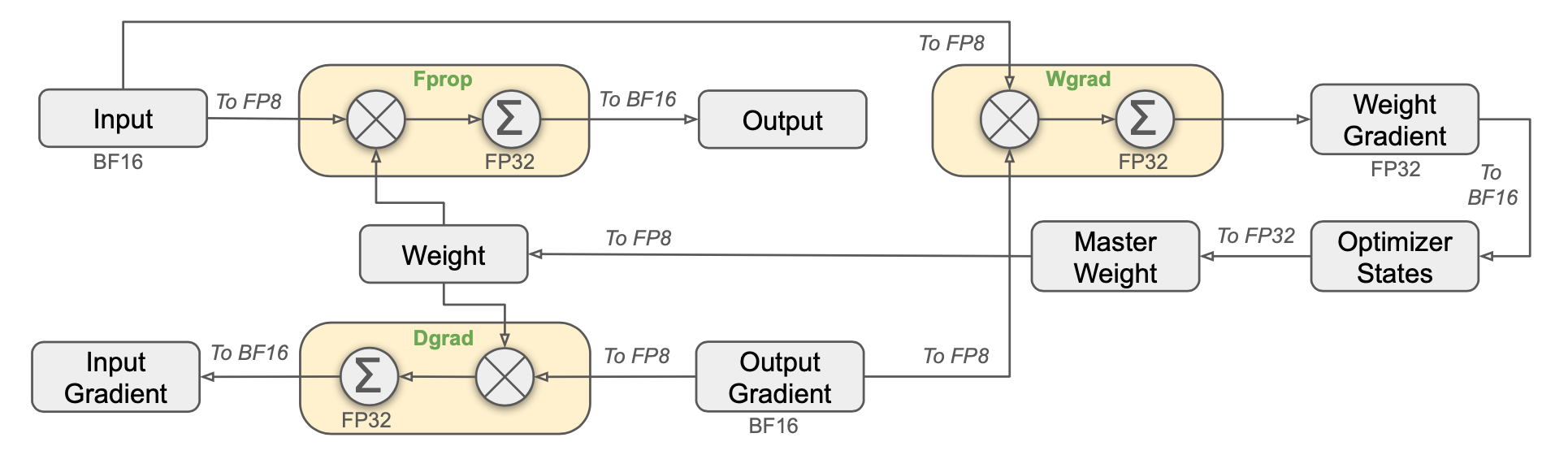
在壓縮 FP8 的過程中,如果直接將 BF16 做裁切,可能會造成 overflow 或 underflow。 一個可能的方法是依據 data scale 做 normalization,然而這樣會容易受到 outliers 的影響,導致模型性能下降。 DeepSeek 使用一種簡單的方式稱作 fine-grained quantization,將原始浮點數的範圍分成 128 組,再將量化結果填入,使其能夠均勻分布。
DualPipe Algorithm
在 LLM 訓練與推理的時候,我們經常會遇到一個問題,那就是模型實在太大了,GPU memory 不夠用。 有鑑於此,目前發展出許多平行處理 (parallelism) 的技巧,例如 data parallelism、model parallelism、pipeline parallelism 等。 DeepSeek 是採用 pipeline parallelism,也就是將模型的 layers 分佈到不同的 GPU 上運算。 這麼做的缺點是每個 GPU 都必須等待前一層 layer 執行完,造成 pipeline bubble。 針對這個問題有很多基於演算法的優化方式,例如經典的 1F1B 11。

DeepSeek 自己開發了 DualPipe 演算法,將資料「運算」與「傳輸」所需要花費的時間考慮進去,利用一對 forward 與 backward 做搭配,讓 GPU 的使用率盡可能最大化。 根據論文,這種作法幾乎可以減少 50% 的 pipeline bubble,只需要多複製一份模型參數即可。 搭配其 MoE 架構,可以讓實際運作參數大為降低,體現出這種訓練方式的價值。
Cross-Node All-to-All Communication
DeepSeek V3 使用大量的 H800 來組成叢集,每個節點有 8 個 GPU。 節點內部透過 NVLink 和 NVSwitch 連結 (160 GB/s),節點之間則透過 InfiniBand (IB) 連接 (50 GB/s)。 為了避免 IB traffic,DeepSeek 限制每個 token 只能分配至 4 個 nodes, 並透過 warp specialization technique 12 與改寫 PTX 指令(CUDA 底層),讓 NVLink 與 IB 的傳輸可以重疊,使兩者的頻寬可以被充分使用。 理想上,NVLink 的頻寬是 IB 的 160 / 50 = 3.2 倍,代表最多可以同時有 3.2 * 4 = 12.8 個 MoE 專家被選擇(實際上 8 個)。 這麼做可以大幅增加 GPU 之間溝通的效率。
如果想瞭解更多關於底層優化的細節,可以參考 Laurie Wired 的這段影片:
Distill Reasoning Capability
在 post-training 的階段,DeepSeek V3 使用了蒸餾技術來獲取其推理模型 DeepSeek R1 的能力(例如解數學問題、寫程式)。 儘管 R1 的推理能力很強,生成內容卻可能過於冗長或格式混亂。 有鑑於此,他們先整理兩種資料:<problem, original response> 與 <system prompt, problem, R1 response>。 接著透過 reinforcement learning (RL) 的方式額外訓練幾個專家模型,專門用來生成特定領域的資料給 V3 做 fine-tuning,以此讓 V3 向 R1 對齊。
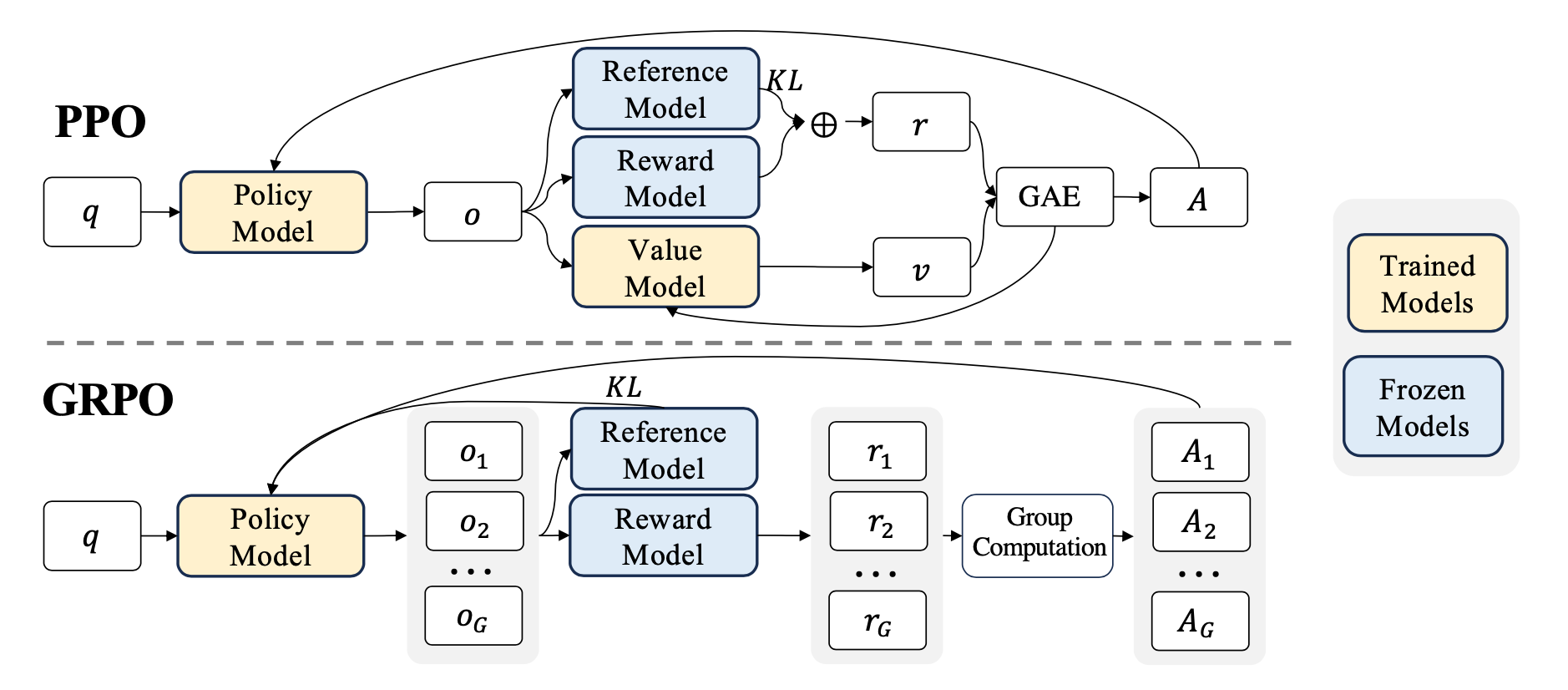
順便一提,對於 DeepSeek V3 自身的 RL,採用 rule-based 與 model-based 兩種 reward model。 前者主要用來評斷有標準的問題,例如數學題、LeetCode 題等;後者主要用來評斷開放式問答,例如寫作。 DeepSeek 開發了自己的 group relative policy optimization (GRPO) 13 算法來取代傳統的 PPO 14,號稱節省資源並提升部分推理表現。 這跟後面要介紹的 R1 模型也有很大的關係。
Evaluation
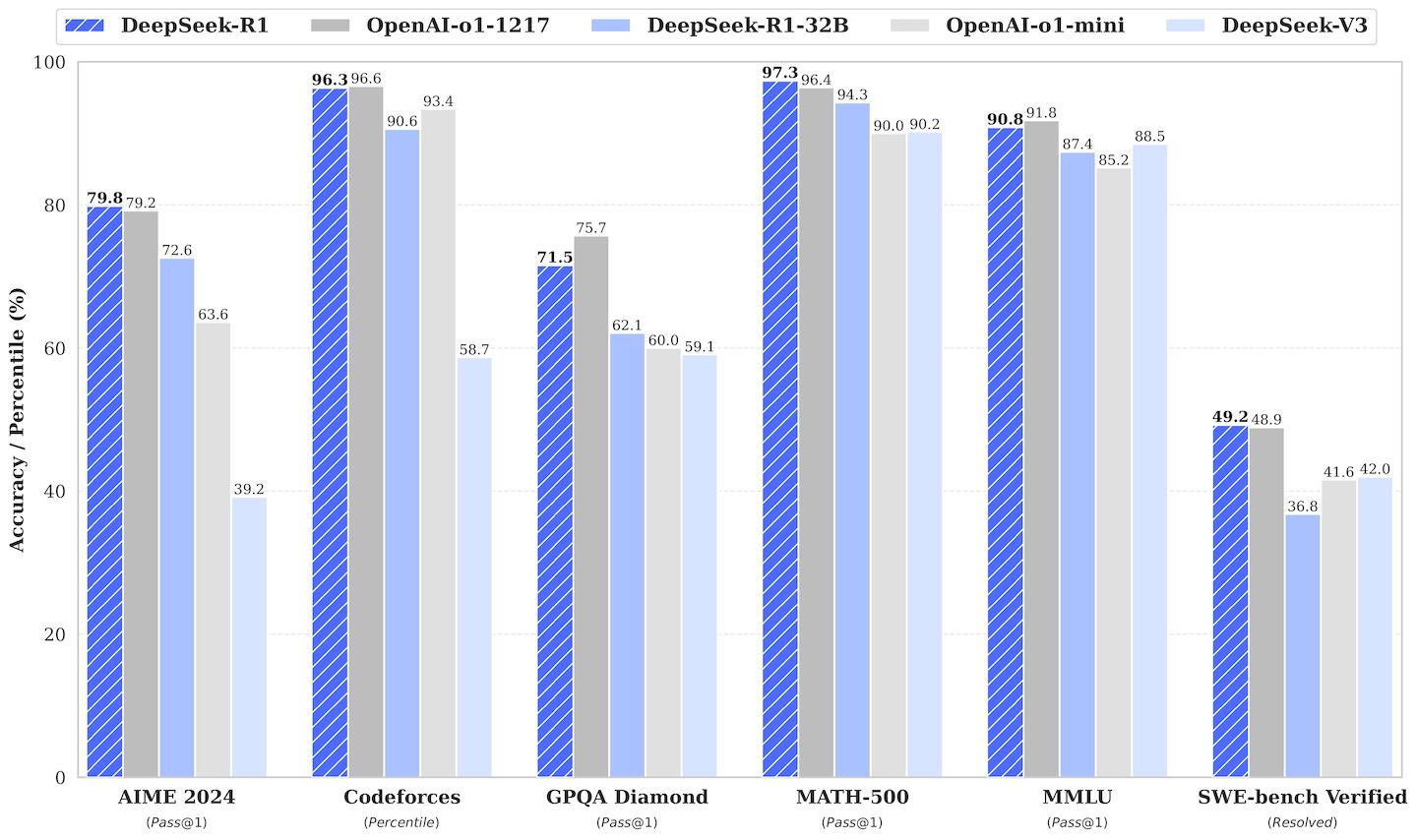
DeepSeek V3 在多個 benchmark 上都有不錯的表現,在 MMLU 中拿下 88.5% 的正確率,超越 GPT-4o 87.2% 與 Claude-Sonnet-3.5 88.3%。 在數學解題上,受惠於 R1 的推理能力,表現相當不凡。AIME 2024 拿下 39.2%,遠超 GPT-4o 9.3% 與 Claude-Sonnet-3.5 16.0%。 MATH-500 拿下 90.2%,也是遠超 GPT-4o 74.6% 與 Claude-Sonnet-3.5 78.3%。
許多方面來說,DeepSeek V3 都超越前一季的閉源頂尖模型。 雖然仍不及當前的 GPT-o1,但是在低成本與年輕團隊下能有這個表現,可說是相當令人驚艷。 雖然沒有真的很創新的發想,但是巧妙融合許多現有技術,並在硬體上進行優化而不是瘋狂堆顯卡,令人耳目一新。
DeepSeek R1
如果說 DeepSeek V3 讓圈內人士驚豔,DeepSeek R1 才是真正在業界掀起巨浪。 因為它真正做到了在 benchmark 上媲美 GPT-o1,甚至在某些領域做到超越。
嚴格來說,R1 系列有兩個版本:R1-zero 與 R1。 R1-zero 最大的貢獻在於,它是第一個不使用 SFT,完全靠 RL 就自主產生推理能力的模型(論文中稱「aha moment」)。 這種感覺很像 2017 年的 AlphaGo Zero,不依賴棋譜,純粹靠自我對弈就產生足以打敗 AlphaGo 的能力 15。 這意味著訓練大型語言模型不再需要大量資料,只需要與 reward model 互動,就可以獨自升級。 奇點是否迫近尚待商榷,可以確定的是訓練門檻又再度被下修了。
DeepSeek R1-zero 作為推理模型,Chains of Thought (CoT) 的能力很強,擅長一步步推導、反思,逐步解開複雜的問題。 它在 AIME 2024 中拿下 71.0%,接近 GPT-o1 74.4%;在 MATH-500 則拿下 95.9%,超越 o1 的 94.8%。 然而作為通用模型就不好用了,因為生成的內容可能過於冗長、格式混亂,讓人不易閱讀。 為了解決這個問題,團隊針對其訓練 pipeline 做了些改良,推出了更全面的 R1 模型。
Cold Start
所謂的冷啟動 (cold start) 是指模型在一開始的階段,對於問題的回答能力不足,需要建立一些策略來避免初期表現太差。 這就像我們推出一個新產品,因為沒有客戶數據,只好從大眾口味先開始著手。 DeepSeek 準備了一堆 few-shot 的 CoT 範本給 DeepSeek-V3-Base 做 fine-tuning, 並規範其輸出格式 |special_token|<reasoning_process>|special_token|<summary>,讓模型回答能夠結構化。
1st RL
微調完模型輸出後,採取跟 R1-zero 一樣的 RL 策略,讓模型自己去學習推理能力。 比較有趣的是,因為中國模型在訓練時會中英混雜,所以回答會有 language mixing。 為了解決這個問題,DeepSeek 多引入了一個 language consistency reward 來處理這個狀況,並在後續階段與推理分數做合併。
Rejection Sampling and SFT
所謂拒絕採樣 (rejection sampling) 是指針對同一個 prompt 產生多組不同答案,並留下最好的結果。 這麼做可以提升模型訓練的品質,同時讓它學會嘗試用不同角度解決推理問題。
在這個階段,模型的目標是解決更泛用、非 rule-based reward 能解決的問題。 針對推理相關問題,使用 DeepSeek V3 輔助產生問題並評斷回答結果,以此產生 60 萬個範本; 對於非推理類問題(例如聊天、寫作),使用 V3 產生類似 CoT 的答案,整理出 20 萬個範本。 最後再將這些 80 萬個範本拿來微調通用模型 DeepSeek-V3-Base,產生出 R1 的雛形。
2nd RL
最後,針對這個 R1 版本做些調整,包含前面提到過為了推理與泛用的 RL。 然後將其做 harmlessness 調整,去除傷害善良風俗的回答(使其符合中國政策)。 最後產出的版本就是 DeepSeek R1。
Evaluation
從本文首圖可見,DeepSeek R1 不論回答通用問題還是推理問題都相當傑出。 MMLU 達到 90.9%,雖然輸給 GPT-o1 91.8% 但超越 Claude-3.5-Sonnet 88.3%,甚至超越作為其基底的 DeepSeek-V3 88.5%。 在推理問題上,AIME 2024 拿下 79.8%,超越 GPT-o1 79.2%、Claude-3.5-Sonnet 16.0%、DeepSeek-V3 39.2%; MATH-500 拿下 97.3%,超越 GPT-o1 96.4%、Claude-3.5-Sonnet 78.3%、DeepSeek-V3 90.2%。 可見經過適當的訓練,DeepSeek R1 從 V3 搖身一變成為當今最強大的推理模型之一。
Distillation
DeepSeek R1 與 V3 簡直是相扶相持的兄弟。由 V3 孕育出 R1,再由 R1 將推理能力蒸餾回 V3。 同樣的知識蒸餾技術也可以拿來運用在其他輕量模型上。 在論文中,團隊將之前微調 R1 用的 80 萬個範本拿來微調阿里巴巴的通義千問 (Qwen) 與 Meta Llama 模型(皆未使用 RL )。 結果相當驚人,就連 Qwen-1.5B 都可以在 AIME 2024 拿下 28.9%,超越 Claude-3.5-Sonnet 16.0%。 如果是 Qwen-14B 就可以來到 69.7%,超越 GPT-o1-mini 的 63.6%。
這些結果顯示 DeepSeek 的訓練方式是有效的,但也同時揭露了模型大小(參數多寡)對於思考能力依然有很大的侷限。 文中也試著將 Qwen-32B 進行如 DeepSeek R1-zero 般的 RL 訓練,結果顯示並沒有比 baseline 更好。 可見小模型無法從 RL 中獲得足夠的運算能力來自我覺醒,但透過大模型的知識蒸餾,便可以將小模型的能力大幅提升。 這是一件非常讓人振奮的事情。
補充:UC Berkeley 的團隊使用 Qwen2.5-3B 成功讓模型透過 RL 產生 CoT 的能力。 Ref: https://github.com/Jiayi-Pan/TinyZero
結語
時至今日,依然有很多人在問:「DeepSeek 推出模型究竟是真是假?美國真的有這麼不堪嗎?」 我覺得這可以從很多面向去討論,但我們不妨參考一下 Anthropic CEO Dario Amodei 的發文:「On DeepSeek and Export Controls」。
Dario Amodei 認為,目前 AI 的訓練成本每年大約降低四倍,所以從幾千萬美元降到幾百萬美元是必然的趨勢,只是這次罕見的由中國公司首先做到。 DeepSeek 確實有一些技術創新(例如 MoE 與 MLA),但上述只是訓練成本,真正的研發成本並不比美國公司低。 許多證據顯示其母公司幻方量化擁有大量的 H100 與 H800 GPU,總價值不低於 10 億美元。 而這又牽扯到美國的晶片禁令是否真的奏效?畢竟我們都知道中國擅長從第三方國家偷運晶片(例如新加坡)。
另外,也有人提到不合法的資料取得問題。OpenAI 宣稱掌握 DeepSeek 從 GPT 蒸餾資料的證據 16,而相關使用條款明文禁止這樣的行為。 不過其實除了 Google 與 Meta,沒幾間科技公司真的掌握大量合法資料。 就連 OpenAI 去年也曾被《紐約時報》控告非法取用其資料來訓練模型 17,可見在這個領域大家都是半斤八兩。 DeepSeek 可能也沒想到自己會突然爆紅成這樣,變得所有行為都被放大檢視。
然而,根據目前的使用結果與第三方 benchmark 來看,DeepSeek R1 確實有著頂尖的能力。 不論其訓練成本是否真的如宣稱般低,其開源的行為對於 AI 領域來說依然是相當正面的衝擊。 Perplexity 在 R1 推出幾週後,就著手改造出移除中國言論審查的 R1-1776,並開源在 Hugging Face 上供大家使用 18。 其他大公司如 Microsoft Copilot 和 Nvidia NIM 也導入 R1 模型,可見其漸漸被市場採納進現有的商業體系中。

AI 領域蓬勃發展,模型與技術更是日新月異。 短短幾天,阿里巴巴就推出更強大的通用模型 Qwen-2.5-Max,號稱超越 DeepSeek V3。 過沒多久,OpenAI 也發表下一代推理模型 GPT-o3-mini 以及更強大的通用模型 GPT-4.5。 一個月後,Anthropic 推出 Claude-3.7-Sonnet,xAI 也推出 Grok3 模型。 就現況而言,美國在 AI 領域依舊保持領先地位。 然而中國等新興勢力的加入,勢必讓 AI 的發展與競爭更加激烈。
最後我們可以看一下去年中國媒體《暗湧》對 DeepSeek 創始人梁文鋒的 專訪。 梁文鋒認為,創新是一種信念,而矽谷之所以創新能力強,正是因為他們勇於嘗試。 在 AI 這種不斷更迭的領域,封閉式的護城河無法持久。 即便如 OpenAI 般閉源,也無法阻止其他公司迎頭趕上。 真正的護城河應該在公司團隊的成長和技術的累積,這正是一種勇於創新的文化。 同時他也樂觀看待,不論是五年還是十年,我們這代人終究可以看到通用人工智慧 (AGI) 的出現。
補充:兩個月後,中國新創公司 Manus AI 發表通用型 AI agent,Anthropic 也推出了 MCP 的功能,讓人感覺又往 AGI 邁進了一步。
Footnotes
Daya Guo, et al. "Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning." arXiv preprint arXiv:2501.12948 (2025). ↩
DeepSeek-R1 Release, URL: https://api-docs.deepseek.com/news/news250120 ↩
DeepSeek AI model sends shockwaves through US tech firms as stocks plunge, Yahoo! finance, URL: https://uk.finance.yahoo.com/news/deepseek-ai-model-sends-shockwaves-080813897.html ↩
Aixin Liu, et al. "Deepseek-v3 technical report." arXiv preprint arXiv:2412.19437 (2024). ↩ ↩2
Sam Altman, Twitter, URL: https://twitter.com/sama/status/1884066337103962416 ↩
Introducing DeepSeek-V3, URL: https://api-docs.deepseek.com/news/news1226 ↩
Dmitry Lepikhin, et al. "Gshard: Scaling giant models with conditional computation and automatic sharding." arXiv preprint arXiv:2006.16668 (2020). ↩
Damai Dai, et al. "Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models." arXiv preprint arXiv:2401.06066 (2024). ↩
Aixin Liu, et al. "Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model." arXiv preprint arXiv:2405.04434 (2024). ↩ ↩2
Fabian Gloeckle, et al. "Better & faster large language models via multi-token prediction." arXiv preprint arXiv:2404.19737 (2024). ↩
Aaron Harlap, et al. "Pipedream: Fast and efficient pipeline parallel dnn training." arXiv preprint arXiv:1806.03377 (2018). ↩
Michael Bauer, Sean Treichler, and Alex Aiken. "Singe: Leveraging warp specialization for high performance on gpus." Proceedings of the 19th ACM SIGPLAN symposium on Principles and practice of parallel programming. 2014. ↩
Zhihong Shao, et al. "Deepseekmath: Pushing the limits of mathematical reasoning in open language models." arXiv preprint arXiv:2402.03300 (2024). ↩
John Schulman, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017). ↩
David Silver, et al. "Mastering the game of go without human knowledge." nature 550.7676 (2017): 354-359. ↩
OpenAI says it has evidence China's DeepSeek used its model to train competitor, Financial Times, URL: https://www.ft.com/content/a0dfedd1-5255-4fa9-8ccc-1fe01de87ea6 ↩
Lawsuit: United States District Court Southern District of New York, Case 1:23-cv-11195 Document 1 Filed 12/27/23 Page 1-69, URL: https://nytco-assets.nytimes.com/2023/12/NYT_Complaint_Dec2023.pdf ↩
Perplexity, "Open Sourcing R1-1776", URL: https://www.perplexity.ai/hub/blog/open-sourcing-r1-1776 ↩ ↩2